- Research
- Open access
- Published:
Building a Chinese discourse topic corpus with a micro-topic scheme based on theme-rheme theory
Big Data Analytics volume 2, Article number: 9 (2017)
Abstract
Background
How to build a suitable discourse topic structure is an important issue in discourse topic analysis, which is the core of natural language understanding. Not only is it the key basic unit to implement automatic computing, but also the key to realize the transformation from unstructured data to structured data during the process of big data analytics. Although the discourse topic structure has wide potential for application in discourse analysis and related tasks, the research on constructing such discourse resources is quite limited in Chinese language. In this paper, we propose a micro-topic scheme (MTS) to represent the discourse topic structure in the Chinese language according to theme-rheme theory, with elementary discourse topic unit(EDTU) as the node and referent of theme-rheme as link. In particular, thematic progression is employed to directly represent the development of the discourse topic structure.
Results
Guided by the MTS, we manually annotate a Chinese Discourse Topic Corpus (CDTC) of 500 documents. Moreover, we get 89.9 and 72.15 F1 value in two identification preliminary experiments, respectively, which show that the proposed representation can perform good automatic computation.
Conclusion
The lack of the formal representation system and related corpus resources for Chinese discourse topic structure has greatly restricted the study of discourse topic analysis in natural language, and further affected the development of natural language understanding. To address the above issues, a micro-topic scheme(MTS) representation is proposed based on functional grammar theory, and the corresponding corpus resources(i.e., CDTC) are constructed. Our preliminary evaluation justifies the appropriateness of the MTS for Chinese discourse analysis and the usefulness of our CDTC.
Background
It is one of the most challenging tasks for the development of artificial intelligence to make it possible for the machine to understand the text of natural language and even understand the intention of the author. Discourse topic structure analysis is the core work of this task, the main research contents are the analysis of discourse topic structure and semantic relations between the units from the whole text level, and use the context of discourse comprehension.
Discourse topic structure is also the key to the cohesion of the discourse and reflects the essence of the text [1]. Over the last few years, discourse topic structure has been widely studied and proven to be a critical cohesive element at the text level [2–7]. A linear segmentation of texts into proper topic structures may reveal valuable information on, for instance, not only the themes of segments but also the overall thematic structure of the text, and it can subsequently be applied to various text analysis tasks, such as text summarization, information retrieval and discourse analysis [8–10].
Although the discourse topic structure has wide potential for application in discourse analysis and related tasks, the research on constructing such discourse resources is quite limited [2, 3], and the focus has mostly rested on the English language except some other research [11, 12]. However, as far as discourse information structure is concerned, English is typologically different from Chinese: the former is a subject-prominent language, where the subject is an indispensable element in determining sentence patterns, and the latter is a topic-prominent language, where the topic makes an important contribution to generate a sentence [13]. This largely differentiates the discourse topic structures in English and Chinese. Unfortunately, previous studies on discourse topic structure fail to fully reflect this difference.
In order to explore the appropriate Chinese discourse topic structure representation, we proposed a micro-topic scheme (MTS) to represent discourse topic structure in the Chinese language according to theme-rheme theory. Subsequently, an automatic analysis system of MTS was constructed for exploring the automatic recognition of Chinese discourse topic.
To the best of our knowledge, this is the first exploration of the use of theme/rheme as a basic unit of discourse structure analysis and the use of thematic progression as a link of discourse relationship analysis in Chinese discourse. Firstly, this model provides a new way of big data processing, which implements a transformation that converts unstructured data to structured data in text. Furthermore, compared with traditional methods, our model has better computability. Automatic recognition for theme/rheme task is associated with most pop research topics in the area of natural language processing, e.g., POS tagging, semantic role labeling (SRL). Effective research on these tasks contributes to improve the computational performance of our current task more easily.
The rest of this paper is organized as follows. “Related work” section briefly overviews the related work. In “Model” section, we present the MTS according to theme-rheme theory, and describe the construction of the CDTC corpus. In “Methods” section, an automatic analysis method of MTS is proposed. “Results and discussion” section provides the experimental result on the identification of entities of MTS, the crucial step for automatic discourse topic analysis. Finally, “Conclusion” section concludes our work.
Related work
The rhetorical structure and the topic structure are not only interdependent but also complemental in discourse analysis.
For the discourse rhetorical structure, with Rhetorical Structure Theory Discourse Treebank (RST-DT) [2] and Penn Discourse Treebank (PDTB) [3] being the most prevalent over the past decade, the emergence of several English corpus provides resources for the analysis of English discourse. In contrast, there are only a few studies on Chinese discourse annotation [14–17], with a focus on using the existing RST (Rhetorical Structure Theory) or PDTB frameworks. Recently, Li et al. (2014) proposed a Connective-driven Dependency Tree (CDT) structure as a representation scheme for Chinese discourse structure [18]. With both the advantages of PDTB and RST, CDT meets well the special characteristics of Chinese discourse.
For the discourse topic structure, some studies have begun to focus on the topic level in Chinese discourse topic annotation. The OntoNotes corpus [4] was built on two types of infrastructure, the syntax structure and the predicate-argument structure, which were derived from the Penn Treebank corpus and the Penn PropBank corpus, respectively. In addition, the generalized topic framework [5] defines punctuation clauses as the basic unit of Chinese discourse, and the concepts of the generalized topic and the topic clause is proposed to explicitly describe the topic structure in Chinese discourse. Although both the OntoNotes corpus and the generalized topic framework take into account the special characteristics of Chinese discourse, some issues still remain. For example, there is no suitable representation unit to match different levels of topics. In addition, the lack of sufficient corpus resources to meet the research of Chinese discourse topic analysis is also a serious problem.
Model
Micro-Topic Scheme
In order to explore the discourse relationship, we propose a micro-topic scheme (MTS) to represent the discourse cohesion according to the theme-rheme structure based on functional grammar theory [19], which can be formalized as a triple as below:
Where S n ∈T∪R, S n+1∈T∪R, T represent the set of themes and R is the set of rhemes in the whole discourse,called Static Entities of MTS by us. δ n ∈L, L is a set of cohesion dynamic relationships of MTS between EDTUs, called Micro-Topic Link(MTL) by us. The visual representation of the model is shown in part (b) of the Fig. 1 below. Some definitions in the model are as follows.

An example of discourse topic structure in MTS with the corresponding discourse rhetorical structure. According to a connective-driven dependency tree (CDT) scheme, connectives were directly used to represent the hierarchy structure of a CDT and the rhetorical relation of a discourse, as shown in part (a) of this Figure. Part (b) in this Fig. 1 gives an example of MTS representation, corresponding to Example 10 shown in manuscript. It consists of 7 clauses, excerpted from chtb0001 which is from OntoNotes corpus. Here, a clause is equivalent to an EDTU, which is constituted by a theme and a rheme, denoted by Tx and Rx, respectively
Definition 1
is defined as the basic unit of discourse topic analysis, which is limited to clause.
Inspired by Rhetorical Structure Theory, an EDTU should contain at least one predicate and express at least one proposition. Moreover, an EDTU should be related to other EDTUs with some propositional function. Finally, an EDTU should be punctuated. For Example 1, (a) is a single sentence with serial predicate; (b) is a complex sentence with two EDTUs(clauses).
Example 1
-
(a)
She started the car. (single sentence, serial predicate, one EDTU)
-
(b)
She started the car, and drove off.(complex sentence, two EDTUs)
In order to improve the computational performance, we give the main structure of Theme and Rheme as defined in Definition 2.
Definition 2
(Theme and Rheme) Theme Structure is the left part of the predicate in the EDTU for Chinese, and the remainder is Rheme Structure.
Taking Example 1 as an example, we can find that She is the Theme, and started the car is the Rheme.
Definition 3
(Micro-Topic Link (MTL)) A MTL is a representation of the semantic association between the themes or rhemes, which are derived from the adjacent EDTUs. This semantic association is expressed as four thematic progression patterns formally, while in content, it reflects the cohesive properties of the discourses, which mainly include reference, ellipsis, substitution, repetition, synonym/antisense, hyponymy, meronymy, and collocation.
∙Reference means that the current theme(or rheme) in an EDTU refers to the previous one.
Example 2
-
(a)
[
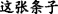 ]
T1[
]
T1[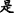 (
(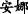 )
Nucleus
)
Nucleus
 ]
R1, (b) [
]
R1, (b) [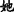 ]
T2=R1(N
u
c
l
e
u
s)
]
T2=R1(N
u
c
l
e
u
s)

-
(a)
[This note] T1 [was left by [Anna] N u c l e u s ] R1, (b) [who] T2=R1(N u c l e u s) had just come.
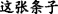 ]
T1[
]
T1[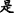 (
(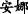 )
Nucleus
)
Nucleus
 ]
R1, (b) [
]
R1, (b) [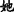 ]
T2=R1(N
u
c
l
e
u
s)
]
T2=R1(N
u
c
l
e
u
s)

In the above Example 2, EDTU(a) and EDTU(b) constitute a MTS through a MTL, which is a connection of reference between “ (Anna)” and “
(Anna)” and “ (who)”. Among them, “
(who)”. Among them, “ (was left by Anna)” is the rheme of EDTU(a), and “
(was left by Anna)” is the rheme of EDTU(a), and “ (who)” is the theme of EDTU (b).
(who)” is the theme of EDTU (b).
∙Ellipsis means that the theme or rheme of the second EDTU is omitted, which is a kind of grammatical method to avoid repetition, highlight new information, and make the text more compact. As shown in Example 3, theme “ (I)” was omitted in EDTU (b).
(I)” was omitted in EDTU (b).
Example 3
-
(a)
[
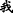 ]
T1[
]
T1[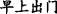 ]
R1, (b) [ZeroA]
T2=T1[
]
R1, (b) [ZeroA]
T2=T1[ ]
R2.
]
R2. -
(a)
[I] T1 [ went out in the morning] R1 (b) and [ZeroA] T2=T1 [ saw a cat] R2.
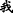 ]
T1[
]
T1[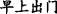 ]
R1, (b) [ZeroA]
T2=T1[
]
R1, (b) [ZeroA]
T2=T1[ ]
R2.
]
R2.∙Substitution means that the theme(or rheme) in the latter EDTU is replaced by a substitute for words, which has the same meaning as the replaced component. As shown in Example 4, rheme “ (a new one)” was an substitute word in EDTU (b) for the replaced component, which is “
(a new one)” was an substitute word in EDTU (b) for the replaced component, which is “ (Steve’s hat)”.
(Steve’s hat)”.
Example 4
-
(a)
[
 ]
T1[
]
T1[ ]
R1, (b) [
]
R1, (b) [ ]
T2[
]
T2[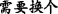 [
[ ]
Nucleus
]
R2(N
u
c
l
e
u
s)=T1
]
Nucleus
]
R2(N
u
c
l
e
u
s)=T1

-
(a)
[Steve’s hat] T1 [ is too broken] R1. (b) [He] T2 [ needs [a new one] Nucleus ] R2(Nucleus)=T1.
 ]
T1[
]
T1[ ]
R1, (b) [
]
R1, (b) [ ]
T2[
]
T2[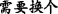 [
[ ]
Nucleus
]
R2(N
u
c
l
e
u
s)=T1
]
Nucleus
]
R2(N
u
c
l
e
u
s)=T1

∙Repetition means that the theme(or rheme) has appeared many times, such as “  (bear)” in Example 5.
(bear)” in Example 5.
Example 5
-
(a)
[
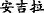 ]
T1[
]
T1[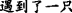 [
[ ]
N
u
c
l
e
u
s
]
R1, (b) [
]
N
u
c
l
e
u
s
]
R1, (b) [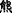 ]
T2=R1(N
u
c
l
e
u
s)
]
T2=R1(N
u
c
l
e
u
s)
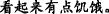
-
(a)
[Algy] T1 [met [a bear] Nucleus ] R1. (b) [The bear] T2=R1(Nucleus) looks a bit hungry.
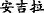 ]
T1[
]
T1[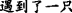 [
[ ]
N
u
c
l
e
u
s
]
R1, (b) [
]
N
u
c
l
e
u
s
]
R1, (b) [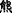 ]
T2=R1(N
u
c
l
e
u
s)
]
T2=R1(N
u
c
l
e
u
s)
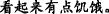
∙Synonym/antisense means that the themes(or rhemes) related to two EDTUs are a pair of synonyms or antonyms. Example 6 shows that “ (a friend)” and “
(a friend)” and “ (enemy)” is a pair of antonyms.
(enemy)” is a pair of antonyms.
Example 6
-
(a)
[
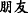 ]
T1[
]
T1[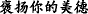 ]
R1, (b) [
]
R1, (b) [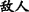 ]
T2=T1[
]
T2=T1[ ]
R2
]
R2

-
(a)
[A friend] T1 [praises a man’s virtue] R1, [and the enemy] T2=T1 exaggerates his fault.
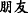 ]
T1[
]
T1[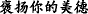 ]
R1, (b) [
]
R1, (b) [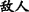 ]
T2=T1[
]
T2=T1[ ]
R2
]
R2

∙Hyponymy means that the themes(or rhemes) related to two EDTUs form an abstract and concrete relationship. As shown in Example 7, “ (wolf)” is a kind of “
(wolf)” is a kind of “ (animal)”.
(animal)”.
Example 7
-
(a)
[
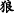 ]
T1[
]
T1[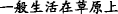 ]
R1, (b) [
]
R1, (b) [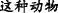 ]
T2=T1
]
T2=T1
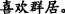
-
(a)
[The wolves] T1 [usually live on the grassland] R1, (b) [and the animals] T2=T1 like to live in groups.
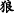 ]
T1[
]
T1[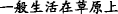 ]
R1, (b) [
]
R1, (b) [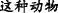 ]
T2=T1
]
T2=T1
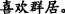
∙Meronymy means that the theme(or rheme) in one EDTU is a part of the theme(or rheme) from the other EDTU. As shown in Example 8, “ (his hair)” is a part of “
(his hair)” is a part of “ (A middle-aged man)”, from the point of view of body composition.
(A middle-aged man)”, from the point of view of body composition.
Example 8
-
(a)
[
 ]
T1[
]
T1[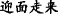 ]
R1, (b) [
]
R1, (b) [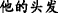 ]
T2=T1
]
T2=T1

-
(a)
[A middle-aged man] T1 [is walking on the head] R1, (b) [his hair] T2=T1 is very bright.
 ]
T1[
]
T1[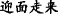 ]
R1, (b) [
]
R1, (b) [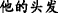 ]
T2=T1
]
T2=T1

∙Collocation means that the themes(or rhemes) related to two EDTUs belong to a set of semantically related words. There are two groups of words as follows, for instance, “ice, snow, white” and “night, star”.
Example 9
-
(a)
[
 ]
T1[
]
T1[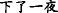 ]
R1, (b) [
]
R1, (b) [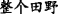 ]
T2[[
]
T2[[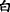 ]
Nucleus
]
Nucleus
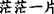 ]
R2=T1
]
R2=T1

-
(a)
[Snow] T1 [had fallen all night] R1, (b) [while the fields] T2 [were a vast expanse of [whiteness] Nucleus ] R2=T1.
 ]
T1[
]
T1[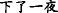 ]
R1, (b) [
]
R1, (b) [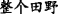 ]
T2[[
]
T2[[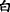 ]
Nucleus
]
Nucleus
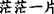 ]
R2=T1
]
R2=T1

In the above Example 9, “snow” and “whiteness” constitute the MTL, which is a connection between EDTU(a) and EDTU(b).
Definition 4
A DT is composed of n MTSs(n≥1), which are connected by MTLs.
In fact, the DT is a recursive definition, which can be expressed as follows:
-
Rule (1) A MTS is a DT.
-
Rule (2) Two DTs connected with MTL is a DT.
-
Rule (3) DT belongs to the union of all sets satisfying Rule (1) and Rule (2).
Definition 5
A MTC is a sequence of connected MTLs, which are contained in a DT.
The topic chain is a common phenomenon in Chinese. The contextual referring expressions are frequently omitted in Chinese discourse, which leads to the difficulty associated with the topic chain [20]. Typically, in order to enable the reader to find a specific discourse coherence, the referring expression has sufficient topic continuity. And above all, a topic chain will be made up of the identical topics which linked by anaphora (zero anaphora or not) [21].
To illustrate our proposed MTS, we give an Example 10 as below.
Example 10
(1)[[ ]
Satellite
]
Satellite
 ]
T1[
]
T1[  ,
, 

 ]
R1, (2) [ <ZeroA>
Nucleus
(
]
R1, (2) [ <ZeroA>
Nucleus
( )
) ]
T2(Nucleus)=T1(Satellite)[
]
T2(Nucleus)=T1(Satellite)[
 ]
R2
]
R2
 (3) [(
(3) [( ), ]
T3=T2(Nucleus) [
), ]
T3=T2(Nucleus) [ “
“ ,
,  ”
”  ]
R3,(4)[ <Z
e
r
o
A>]
T4=T3[
]
R3,(4)[ <Z
e
r
o
A>]
T4=T3[ ]
R4,(5)[ <ZeroA>]
T5=T4 [<
]
R4,(5)[ <ZeroA>]
T5=T4 [< >
> ]
R5, (6) [<ZeroA>]
T6=T5[<
]
R5, (6) [<ZeroA>]
T6=T5[< >
> 
 ]
R6, (7)[ <ZeroA>]
T7=T6 [
]
R6, (7)[ <ZeroA>]
T7=T6 [ ]
R7
]
R7

(1)[Pudong’s development and opening] T1 [is an undertaking spanning a century for vigorously promoting Shanghai and constructing a modern economic, trade, and financial center] R1. (2)Because of this, <during the process of [Pudong’s] Satellite development and opening, > ZeroA=T2=T1 [new situations and new questions that were not encountered previously are emerging in great numbers] R2. (3)[In response to this, Pudong] T3=T2(Satellite) [is not simply adopting an approach of “work for a short time and then draw up laws and regulations only after experience has been accumulated.”] R3 (4)[Instead, Pudong] T4=T3 [is taking advantage of the lessons from the experience of developed countries and special regions such as Shenzhen] R4, (5) [<ZeroA>] T5=T4 [by hiring appropriate domestic and foreign specialists and scholars] R5, (6) [<ZeroA>] T6=T5 [actively and promptly formulating and issuing regulatory documents] R6. (7) <According to these documents, >(ZeroA=T7=T6) [these economic activities are incorporated into the sphere of influence of the legal system as soon as they appear] R7.
Li [18] proposed a connective-driven dependency tree (CDT) scheme to represent discourse rhetorical structure in the Chinese language, in which elementary discourse units (EDUs) were used as leaf nodes and connectives were used as non-leaf nodes. Especially, connectives were directly used to represent the hierarchy structure of a CDT and the rhetorical relation of a discourse, as shown in part (a) of the Fig. 1.
Part (b) in Fig. 1 gives an example of MTS representation, corresponding to Example 10 shown above. It consists of 7 clauses, excerpted from chtb0001 which is from OntoNotes corpus. Here, a clause is equivalent to an EDTU, which is constituted by a theme and a rheme, denoted by Tx and Rx, respectively. For instance, “In spite of the fact that of the regulatory documents that the Pudong new region” stands for the theme in the first clause(a), and the rheme occupies the rest, “has formulated”.
Similar to what we described above, we define a DT as a set of MTSs sharing an identical topic connected by MTLs. For example, there are two DTs in Example 10, as shown in part (b) of the Fig. 1: T1←T2←T3←T4←T5←T6, and R6←T7, One MTC is guided by the overt identical NP(Noun Phrase) “
Satellite(T1)
(T1) (Pudong’s development and opening up)”, the DT that spreads over six EDTUs (clauses 1 ∼6). As we can see in Fig. 1, six overt coreferential NPs are considered to form a MTC, with the overt NP (T1) being the head topic of the chain, and the following MTC shares one single topic. In comparison, the other chain refers to the DT “ (regulatory documents)” headed by R6 and followed by T7 (zero anaphora).
(regulatory documents)” headed by R6 and followed by T7 (zero anaphora).
According to the theme-rheme theory [19], there is a reference relationship between the theme or rheme of current EDTU and previous EDTU. As shown in Part(b) of Fig. 1, an arrow is employed to indicate this reference by pointing to the theme or rheme in the EDTU, such as T2=T1, T3=T2, T4=T3, T5=T4, T6=T5 and T7=R6.
Static Entity of MTS
Derived mainly from the systemic-functional grammar [19], theme and rheme are two static entities representing the way in which information is distributed in a clause. While theme indicates the given information serving as the departure point of a message, which has already been mentioned somewhere in text or shared as mutual knowledge from the immediate context, rheme is the remainder of the message in a clause in which theme is developed.
From the view point of discourse analysis, we are interested in the sequences of thematic and rhematic choices creating certain kinds of thematic patterns instead of the actual individual choices of themes or rhemes. Therefore, our scheme to the notion of theme is discourse-oriented, that is, we are most concerned with the role theme fulfills in constructing and developing a discourse dynamic relationship, as opposed to individual sentences.
Dynamic Relationship of MTS
Previous studies [22–24] have claimed that the way in which lexical strings and reference chains interact with theme/rheme is not random; rather the patterns of interaction realize what they refer to as a text’s thematic progression. Figure 2 shows four major dynamic relationships of thematic progression proposed in the literature:

Four dynamic relationships of thematic progression. This figure shows four major dynamic relationships of thematic progression proposed in the literature, e.g., Constant Progression, Centralized Progression, Simple Linear Progression, Crossed Progression
(I) Constant Progression, where the theme of the subsequent clause is semantically equivalent to the theme of the first clause.
Example 11
(a) Two beggars (T1) had been hiding (R1). (b)They(T2=T1) saw the money (R2).
(II) Centralized Progression, where the rheme of the subsequent clause is semantically equivalent to the rheme of the first clause.
Example 12
(a) The children (T1) laughed (R1). (b) Then their mother(T2) laughed, too (R2=R1).
(III) Simple Linear Progression, where the theme of the subsequent clause is semantically equivalent to the rheme of the first clause.
Example 13
(a)Our school (T1) is a big garden (R1). (b)In the garden(T2=R1) grow many flowers (R2).
(IV)Crossed Progression, where the rheme of the subsequent clause is semantically equivalent to the theme of the first clause.
Example 14
(a) The exhibition (T1) was good (R1). (b) I (T2) liked it very much (R2=T1).
As shown in Example 10, constant progression is suitable for the referent relationships among clauses 1-6.
Corpus building based on MTS
Based on this MTS model, we annotated a Chinese discourse topic corpus(CDTC) with 500 discourses from OntoNotes corpus English datasets(chtb0001-chtb0325, chtb0400-chtb0657). To begin with, the same dataset were annotated by two annotators simultaneously. Moreover, we calculate the consistency of annotations with Kappa Value by using the two sets of annotated data. Finally, a formal corpus dataset will be constructed and checked by senior tagging instructor. Table 1 illustrates the inter-annotator consistency specifically. The CDTC is also used for our experiment as dataset.
Methods
Overall processing pipeline
To evaluate the computability of our CDTC corpus, we present the experimental results on the identification of static entity of MTS(i.e., theme-rheme structures), which is a crucial component of discourse topic analysis.
Our model framework is summarized in Fig. 3. This system takes an input discourse and output the confidence score of the entity of MTS. It primarily consists of the following three components: Inputting the discourse, Identifying the EDTUs (Elementary Discourse Topic Units) and Identifying static entity of MTS. To begin with, the input of the system is the discourse from natural language without any preprocessing. In succession, the comma is used as a boundary sign, and the classifier model is obtained by machine learning algorithms. With the help of this classifier model, the input text is split into a number of simple sentences containing a predicate, which is defined as EDTUs. Finally, according to these EDTUs, entities of MTS in which are identified. Take Example 10 as an instance, we will describe each components in our model as below.

The Experimental Framework of Identifying entities of MTS. This system according to which takes an input discourse and output the confidence score of the entity of MTS. It primarily consists of the following three components: Inputting the discourse, Identifying the EDTUs(Elementary Discourse Topic Units) and Identifying static entity of MTS. To begin with, the input of the system is the discourse from natural language without any preprocessing. In succession, the input text is split into a number of simple sentences containing a predicate, which is defined as EDTUs. Finally, according to these EDTUs, entities of MTS in which are identified
Identifying the EDTUs
According to the Definition 1, the Example 10 has 7 EDTUs, which include Clause(a), (b), (c), (d), (e), (f) and (g).
For the automatic identification of EDTU, inspired by Li [18], we consider this as a binary classification for EDTU’s boundary and use some machine learning methods to solve this problem. We used various features listed in Table 2 specifically, which had adopted in [25] and [18]. Table 3 shows the performance of EDTU identification on the CDTC with 10-fold cross validation via the Mallet toolkit [26].
Identifying entities of MTS
According to Definition 2 of subsection Model, the Example 10 has 7 themes and 7 rhemes, which are represented by T1-T7 and R1-R7, respectively.
For the automatic identification of entities of MTS, according to our Definition 2, the predicate is used as a division sign, and thus, the identification of entities of MTS is equivalent to the predicate identification problem in a way. In other words, this problem is transformed into a classical semantic role labeling problem. It is worth noting that the recognition of the predicate is limited to one EDTU range, which would contribute to a better recognition result. In addition to classical predicate features in previous studies [27–29], more features are derived from nominal and verbal SRL(Sematic Role Labeling), such as the location in terms of the NP, the path features, intervening verb and the arguments. Using the Mallet toolkit [26] with features listed in Tables 4 and 5 shows the performance of identifying the entities of MTS on CDTC corpus with 10-fold cross validation.
Results and discussion
Result
Tables 3 and 5 show the result of automatic recognition for the EDTUs and the entities of MTS, respectively.
On the one hand, in order to reflect the independent performance of each module, we extract features from the previous module’s manual tagging as input to the current module. This is called Gold shown in Tables 3 and 5. On the other hand, in order to observe the performance of the overall system, we also use the features automatically acquired by the previous module as input to the current module. This is called Automatic.
As shown in Table 3, we obtained some high F1 values based on the Gold data set, the highest one among which reached 91.9%. Meanwhile, the results based on Automatic data set are also very close to the Gold’s ones, the highest one among which reached 89.9%. The main reason may lie in the clarity of definition of EDTU and less ambiguity.
As shown in Table 5, compared with the model for recognition of the EDTUs, the performance of the module for recognition of the entities of MTS has decreased. This is not only due to the introduction of errors from the previous module, but also owing to the complexity of identifying the entities of MTS. Despite that, MaxEnt performs the best, with a F1 measure as high as 80.05% on gold data and a F1 measure as high as 72.15% on automatic data.
In Summary, the result suggests the appropriateness of our definition of the micro-topic scheme.
Discussion
The importance of MTS lies in constructing a suitable representation for computing the discourse topic. The specific analysis is as follows:
(a) The unified definition of EDTU is consistent with EDU from Rhetorical Structure Theory (RST), which provides the basis for discourse analysis through the joint research of discourse topic structure and discourse rhetorical structure.
(b) The formal definition of MTL involves incorporating a variety of cohesive relations into the scope of semantic relations, which provides a more complete research content for the study of the discourse semantic relations.
(c) The recursive definition of the discourse topic (DT) reflects the level of the topic, which provides a basis for the hierarchical research of discourse topic structure.
(d) In the implementation of MTL, the patterns of thematic regression are introduced, which provide a dynamic evolution process for text generation. In other words, it provides a computable model for text generation.
In sum, (d) is a dynamic analysis process, and (a), (b) and (c) achieve a static representation architecture. On the basis of the combination of the above, the MTS provides a full representation system and a suitable deductive tool for discourse analysis.
Conclusion
In this paper, we propose a micro-topic scheme (MTS) as a representation for Chinese discourse topic structure according to theme-rheme theory. MTS has the advantages of both the OntoNotes corpus and the generalized topic framework and adapts well to the special characteristics of Chinese discourse. Especially, we analyzed the characteristics of MTS in a comprehensive way from the various perspectives of EDTU, Static Entity of MTS(i.e.,theme-rheme structure), Dynamic Relationship of MTS(i.e.,micro-topic link) and micro-topic chain. Based on the MTS scheme, we annotate 500 documents according to a top-down segmentation and chain-backtracking strategy to remain consistent with a Chinese native’s cognitive habits. Evaluation of the CDTC corpus proves the appropriateness of the MTS scheme for Chinese discourse cohesion structure and the usefulness of our CDTC corpus.
Abbreviations
- CDT:
-
Connective-driven dependency tree
- CDTC:
-
Chinese discourse topic corpus
- DT:
-
Discourse topic
- EDU:
-
Elementary discourse unit
- EDTU:
-
Elementary discourse topic unit
- MaxEnt:
-
maximum entropy model MTS: Micro-topic scheme
- MTL:
-
Micro-topic link
- MTC:
-
Micro-topic chain
- NP:
-
Noun phrase
- PDTB:
-
Penn discourse treebank
- RST:
-
Rhetorical structure theory
- RST-DT:
-
rhetorical structure theory discourse Treebank
- SRL:
-
Sematic role labeling
References
De Beaugrande RA, Dressler WU, Vol. 1. Introduction to Text Linguistics. London: Longman; 1981.
Carlson L, Marcu D, Okurowski ME. Building a discourse-tagged corpus in the framework of rhetorical structure theory In: van Kuppevelt J, Smith RW, editors. Current and New Directions in Discourse and Dialogue. Dordrecht: Springer: 2003. p. 85–112.
Prasad R, Dinesh N, Lee A, Miltsakaki E, Robaldo L, Joshi AK, Webber BL. The penn discourse treebank 2.0. In: Proceedings of the 6th International Conference on Language Resources and Evaluation. Marrakech: DBLP: 2008. p. 2961–8.
Weischedel R, Pradhan S, Ramshaw L, Kaufman J, Franchini M, El-Bachouti M, Xue N, Palmer M, Marcus M, Taylor A, Greenberg C, Hovy E, Belvin R, Houston A. OntoNotes Release 4.0. Philadelphia: Linguistic Data Consortium; 2010.
Song R, Jiang Y, Wang J. On generalized-topic-based Chinese discourse structure. In: CIPS-SIGHAN Joint Conference on Chinese Language Processing. Stroudsburg: ACL Press: 2010. p. 23–33.
Zhou G, Li P. Improving syntactic parsing of Chinese with empty element recovery. J Comput Sci Techn. 2013; 28(6):1106–1116.
Rutherford A, Xue N. Improving the inference of implicit discourse relations via classifying explicit discourse connectives. In: Proceedings of the 14th Annual Conference of the North American Chapter of the ACL-HLT. Stroudsburg: ACL Press: 2015. p. 799–808.
Salton G, Singhal A, Buckley C, Mitra M. Automatic text decomposition using text segments and text themes. In: Proceedings of the Seventh ACM Conference on Hypertext. Washington: ACM Press: 1996. p. 53–65.
Du L, Buntine WL, Johnson M. Topic segmentation with a structured topic model. In: Proceedings of the 12th Annual Conference of the North American Chapter of the ACL-HLT. Stroudsburg: ACL Press: 2013. p. 190–200.
Galley M, McKeown K, Fosler-Lussier E, Jing H. Discourse segmentation of multi-party conversation. In: Proceedings of the 41st Annual Meeting on Association for Computational Linguistics. Stroudsburg: ACL Press: 2003. p. 562–9.
Ren CY. A Grammar of Spoken Chinese. Berkeley and LosAngeles: University of California Press; 1968.
ChengXi Q. Chinese Discourse Grammar. Beijing(in Chinese): Beijing language and culture university press; 1998.
Li CN, Thompson SA. Subject and topic: A new typology of language. New York: Academic Press; 1976. pp. 457–89.
Chen L. English and Chinese discourse structure dimension theory and practice. Shanghai: PhD thesis, Shanghai International Studies University; 2006.
Ming Y. Rhetorical structure annotation of Chinese news commentaries. J Chin Inf Process. 2008; 4:2–11.
Xue N. Annotating discourse connectives in the Chinese treebank. In: Proceedings of the Workshop on Frontiers in Corpus Annotations II: Pie in the Sky. Washington: ACM Press: 2005. p. 84–91.
Zhou Y, Xue N. Pdtb-style discourse annotation of Chinese text. In: Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL Press: 2012. p. 69–77.
Li Y, Feng W, Sun J, Kong F, Zhou G. Building Chinese discourse corpus with connective-driven dependency tree structure. In: EMNLP. Stroudsburg: ACL Press: 2014. p. 2105–114.
Halliday MAK, Matthiessen CMIM. An Introduction to Functional Grammar. London: Hodder Education; 2004.
Yeh CL, Chen YC. 442 Zero anaphora resolution in Chinese with partial parsing based on centering theory. In: Proceedings of 2003 International Conference on Natural Language Processing and Knowledge Engineering. Piscataway: IEEE Press: 2003. p. 683–8.
Li W, Vol. 57. Topic Chains in Chinese: A Discourse Analysis and Applications in Language Teaching. München: Lincom Europa; 2005.
Dañes F. Functional sentence perspective and the organisation of text In: Dañes F, editor. Papers on Functional Sentence Perspective. The Hague: Mouton: 1974. p. 106–28.
Fries PH. On the status of theme in English: Arguments from discourse In: Petőfi JS, Sözer E, editors. Micro and Macro Connexity of Texts. Hamburg: H. Buske: 1983. p. 116–52.
Zhu Y. Patterns of thematic progression and text analysis. Foreign Lang Teach Res. 1995; 3:6–12.
Xue N, Yang Y. Chinese sentence segmentation as comma classification. In: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL Press: 2011. p. 631–5.
McCallum AK. Mallet: A machine learning for language toolkit. 2002. http://mallet.cs.umass.edu.
Jiang ZP, Ng HT. Semantic role labeling of nombank: A maximum entropy approach. In: Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL Press: 2006. p. 138–45.
Li J, Zhou G, Zhao H, Zhu Q, Qian P. Improving nominal srl in Chinese language with verbal srl information and automatic predicate recognition. In: Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL Press: 2009. p. 1280–8.
Yang H, Zong C. Multi-predicate semantic role labeling. In: Proceedings of 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL Press: 2014. p. 363–73.
Acknowledgements
This work was supported by the National Natural Science Foundation of China (No.61331011, No.61673290) and Foundation of Key Laboratory in Science and Technology Development Project of Suzhou (No. SZS201609).
Funding
Not applicable.
Availability of data and materials
There is a major part of patent protection of software, and therefore cannot be available online. Some data sets will be public in the near future to allow for repeated results.
Author information
Authors and Affiliations
Contributions
X-fX is the co-designer and software developer of the system, GZ is the co-designer of the system, and the academic advisor for X-fX, two authors have contributed to the write-up of this paper. Both authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Xi, Xf., Zhou, G. Building a Chinese discourse topic corpus with a micro-topic scheme based on theme-rheme theory. Big Data Anal 2, 9 (2017). https://doi.org/10.1186/s41044-017-0023-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s41044-017-0023-7