- Review
- Open access
- Published:
Software architectures for big data: a systematic literature review
Big Data Analytics volume 5, Article number: 5 (2020)
Abstract
Big Data systems are often composed of information extraction, preprocessing, processing, ingestion and integration, data analysis, interface and visualization components. Different big data systems will have different requirements and as such apply different architecture design configurations. Hence a proper architecture for the big data system is important to achieve the provided requirements. Yet, although many different concerns in big data systems are addressed the notion of architecture seems to be more implicit. In this paper we aim to discuss the software architectures for big data systems considering architectural concerns of the stakeholders aligned with the quality attributes. A systematic literature review method is followed implementing a multiple-phased study selection process screening the literature in significant journals and conference proceedings.
Background
Various industries are facing challenges related to storing and analyzing large amounts of data. Big Data Systems become nowadays a very important driver for innovation and growth, by means of the insights and information that is obtained via the excessive processing of data. The business and application requirements vary depending on the application domain. Software architectures of big data systems have been previously studied sporadically/extensively. However, it is not easy to suggest a suitable software architecture for big data systems, when considering also both the application requirements and the stakeholder concerns [1].
The interactions and relations among the elements and all the elements as a whole that are necessary to reason about the system define the architecture of that system [2].. The architecture is constructed considering the driving quality attributes therefore it is important to capture those and analyze how these are satisfied by an architecture [3]. The requirements that are satisfied with the given architecture shall also match with the quality attributes.
In this study, we provide a systematic literature review (SLR) focused on the Software Architectures of the Big Data Systems in terms of the application domain, architectural viewpoints, architectural patterns, architectural concerns, quality attributes, design methods, technologies and stakeholders. The challenging part of the study was screening the publications from various domains. The variety of the application areas of big data systems brings along the dissimilar representations of the system architectures with flexible terminologies. In order to achieve the requirements provided by different stakeholders which derive different architectural configurations, a proper architectural design with consistent terminology is essential. We aim to focus on the software architectures for big data systems considering architecture design configurations derived by architectural concerns of the stakeholders aligned with the quality attributes which are implicit in design of various systems.
The application areas of the big data systems vary from aerospace to healthcare [4, 5], and depending on the application domain, the functional and non-functional concerns vary accordingly, influencing both the architectural choices and the implementation of big data systems. To shed light on the experiences reported in the recent literature with deploying big data systems in various domain applications, we conducted a systematic literature review. Our aim was to consolidate reported experience by documenting architectural choices and concerns, summarizing the lessons learned and provide insights to stakeholders and practitioners with respect to architectural choices for future deployment of big data systems.
The study aims to investigate the big data software architectures based on application domains assessing the evidence considering the interrelation among the data extraction area and the quality attributes with the systematic literature review methodology which is the suitable research method. Our research questions are derived to find out in which domains big data is applied, the motivation for adopting big data architectures and to identify the existing software architectures for big data systems We identified 622 papers with our search strategy. Forty-three of them are identified as relevant primary papers for our research. In order to identify various aspects related to the application domains, we extracted data for selected key dimensions of Big Data Software Architectures, such as current architectural methods to deal with the identified architectural constraints and quality attributes. We presented the findings of our systematic literature review to help researchers and practitioners aiming to understand the application domains involved in designing big data system software architectures and the patterns and tactics available to design and classify them.
Big data
The term “Big Data” usually refers to data sets with sizes beyond the ability of commonly used software tools to capture, curate, manage, and process data within a tolerable elapsed time. In general, Big Data can be explained according to three V’s: Volume (amount of data), Velocity (speed of data), and Variety (range of data types and sources). The realization of Big Data systems relies on disruptive technologies such as Cloud Computing, Internet of Things and Data Analytics. With more and more systems utilizing Big Data for various industries such as health, administration, agriculture, defense, and education, advances by means of innovation and growth have been made in the application areas. These systems represent major, long-term investments requiring considerable financial commitments and massive scale software and system deployments.
The big data systems are applicable to the data sets that are not tolerable by the ability of the generic software tools and systems [6]. The contemporary technologies within the area of cloud computing, internet of things and data analytics are required for the implementation of the big data systems. Such massive scale systems are implemented using long term investments within the industries such as health, administration, agriculture, defense and education [7].
Big data systems analytic capability strongly depends on the extreme coupling of the architecture of the distributed software, the data management and the deployment. Scaling requirements are the main drivers to select the right distributed software, data management and deployment architecture of the big data systems [8]. Big data solutions led to a complete revolution in terms of the used architecture, such as scale-out and shared-nothing solutions that use non-normalized databases and redundant storage [9].
As a sample domain, space business already benefits from the big data technology and can continue improving in terms of, for instance horizontal scalability (increasing the capacity by integrating software/hardware) to meet the mission needs instead of procuring high end storage server in advance. Besides multi-mission data storage services can be enabled instead of isolated mission-dedicated warehouse silos. Improved performance on data processing and analytics jobs can support activities such as early anomaly detection, anomaly investigation and parameter focusing. As a result, big data technology is transforming data-driven science and innovation with platforms enabling real time access to the data for integrated value.
The trend is to increase the role of information and value extracted from the data by means of improving the technologies for automatic data analysis, visualization and use facilitating machine learning and deep learning or utilizing the spatio-temporal analytics through novel paradigms such as datacubes.
Systematic reviews
The systematic literature review is a rigorous activity that is applied screening the identified studies and evaluating such studies based on the defined research questions, topic areas or phenomenon of interest. As a result of the evidence gathered for a particular topic, the gaps can be investigated further with supporting studies.
Evidence-based research is successfully conducted initially in the field of medicine and similar approaches are adopted in many other disciplines. Among the goals of the evidence-based software engineering, the quality improvement, assessing the application extent of the best practices for the software-intensive systems can be listed. Besides the evidence based guidelines can be provided to the practitioners as a result of such studies. Considering the benefits of the evidence based research, its application is valuable also in the software engineering field.
The systematic literature review shall be transparent and objective. Defining clear inclusion/exclusion criteria for the selected primary studies is critical for the accuracy and consistency of the output of the review. Well defined inclusion/exclusion criteria minimizes the bias and simplifies the integration of the new findings.
Software architectures
The software architecture is the high-level representation and definition of a software system providing the relationships between architectural elements and sub-elements with a required level of granularity [3, 10]. Views and beyond is one of the approaches to define and document the software architectures [11]. Viewpoints are generated to focus on relevant quality attributes based in the area of use for the stakeholder and more than one viewpoint can be adopted depending on the complexity of the defined system. In order to solve common problems within the architecture, architectural patterns are designed within the relevant context. Architectural patterns, templates and constraints are consolidated and described in viewpoints.
Research method
In this study, the SLR is applied for the software architectures of big data systems following the guidelines proposed in [12, 13] by Kitchenham and Charters. The review protocol that is followed is defined in the following sections.
Review Protokol
In order to apply the systematic literature review, a review protocol shall be defined with the methods to be used for reducing the overall bias. Figure 1 below shows the review protocol that is followed throughout this study:
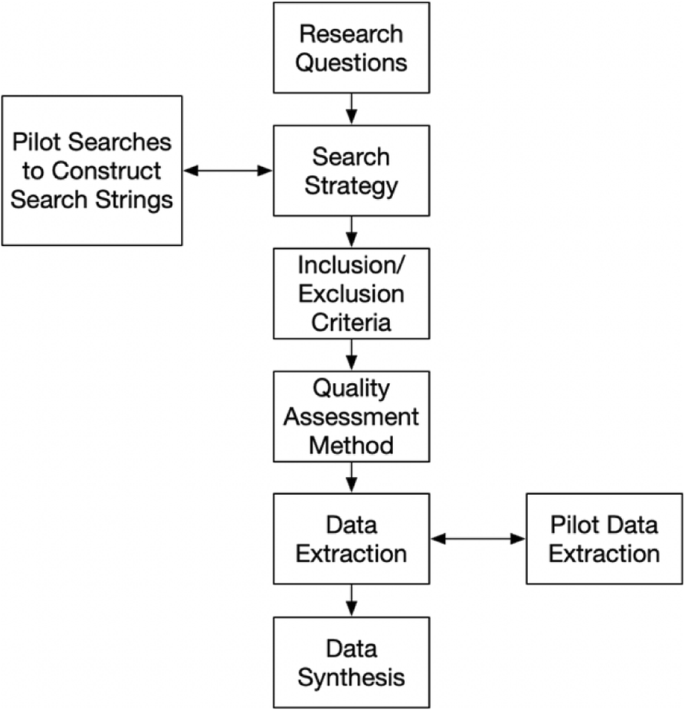
Review Protocol
The research questions are defined using the objectives of the systematic review as discussed in section 3.2 which is followed by drawing the scope (time range and publication resources) and the strategy (section 3.3). The search strategy is shaped by conducting pilot searches to form the actual search strings.
The appropriate definition of the search string reduces the bias and helps to achieve the target precision. The inclusion/exclusion criteria (section 3.4) is defined as the next step. The primary studies are filtered applying the inclusion/exclusion criteria. The success of the study selection process is assessed via the peer reviews of the authors.
The selected primary studies are passed through a quality assessment (section 3.5). Afterwards the data extraction strategy is built to gather the relevant information from the selected set of studies (section 3.6). The data extraction form is constructed and filled with the corresponding output to present the results of the data synthesis.
Research questions
Constructing the research questions in the right way increases the relevancy of the findings and the accuracy of the SLR output. Validity and significance of the research questions is critical for the target audience of the SLR. Considering the fact that we are investigating the software architectures of the big data systems, the following research questions are defined to examine the evidence:
-
RQ.1: In which domains is big data applied?
-
RQ.2: Why are the big data architectures applied?
-
RQ.3: What are the existing software architecture approaches for big data systems?
-
RQ.4: What is the strength of evidence of the study?
Search strategy
In this section, our search strategy is defined to find as many primary studies as possible regarding the research questions listed in section 3.2.
Scope
The search scope of our study consists of the publication period as January 2010 and December 2017 and search databases such as: IEEE Xplore, ACM Digital Library, Wiley Inter Science Journal Finder, ScienceDirect, Springer Link. Our targeted search items were both journal and conference papers.
Method
Automatic and manual search are applied to search the databases.
In order to gather the right amount of relevant studies out of a high number of search process outputs, the selection criteria shall be aligned with the objectives of the SLR. A search strategy with high recall causes false positives and a precise search strategy will narrow down the outcome.
Initially a manual survey is conducted to analyze and bring out the search strings. Using this outcome, search queries are formed and run to obtain the right set of studies with optimum precision and recall rates.
The right method shall be applied to design the search strings with the relevant set of keywords which is critical for optimum retrieval of the studies. The keywords within the references section shall be eliminated and the keywords of the authors shall have higher weight. By means of the concrete set of keywords, the final search string is formed.
After the construction of the search strings, they are semantically adapted to the electronic data sources and extended via OR and AND operators. A sample search string is presented below:
Query 1:
(((“Abstract”: “Big Data” OR “Publication Title”: “Big Data”) AND (p_Abstract: “Software Architecture” OR “Abstract”: “System Architecture” OR “Abstract”: “Cloud Architecture” OR “Publication Title”: “Architecture”)))
Other search strings can be found in Appendix 1. Eliminating the duplicate publications, 662 papers are detected.
Study selection criteria
In order to omit the studies that are irrelevant, out of scope or false positive, aligned with the SLR guidelines, we apply the following exclusion criteria:
-
EC 1: Papers that does not state a big data architecture description, or a big data application that applies an architecture.
-
EC 2: Papers that are not related to a field of computer science.
-
EC 3: Papers are written in different language than English
-
EC 4: Workshop papers
-
EC5: Papers that does not discuss (or discuss partially) the big data architecture
-
EC6: Papers don’t explicitly present the architectural representation/view/model
After the exclusion criteria is applied, the reduced amount of studies are presented in Table 1 where after applying EC1-EC5, which narrowed down our corpus to 341 papers. After applying criterion EC6, we concluded with 43 papers.
Study quality assessment
The quality of the selected studies shall also be assessed based on a checklist. The aim of the quality assessment is the improvement of the relevance and importance of the results via fine tuning the inclusion/exclusion criteria, driving the interpretation of the results (data extraction and synthesis) and recommendations. The checklist should be constructed considering the factors for each study. The factors that have a biasing effect on the outcome are used to form the quality checklist presented in Table 2. The studies are ranked according to the three point scale with the corresponding assigned scores (yes = 1, somewhat = 0.5, no = 0). The assessment results can be found in Appendix 2 (List of Primary Studies).
Data extraction
The data is extracted from the 43 studies selected targeting the review questions and study quality criteria. The standard columns such as title, date, author are included in the data extraction form, in addition to the data extraction columns aligned with the research questions which are application domain, architectural viewpoints, patterns, concerns, quality attributes, etc. The field categories and fields are listed in Table 3.
Data synthesis
After gathering the data aligned with the data extraction form, the data is synthesized to obtain the answers for the predefined research questions. The qualitative assessment is covered interpreting the content of the data and assessing its relevance and relation with other categories/columns while the quantitative assessment is accomplished calculating the quality score for reporting, relevance, rigor and credibility.
We investigated whether the qualitative results can lead us to explain quantitative results. We realized that application architectures are seldom based on a reference architecture in the papers that we reviewed. The analyzed papers mainly elaborate and evaluate the target area using test cases, experiments and other methods that are quantitative in nature however the data used is not available for each case. They also target the research audiences beyond computer science, and the reported data from the computer science point of view is rather limited. The coverage of a possible statistical analysis is not sufficient, however qualitative analysis is applicable for our case.
The data synthesized is transferred to tabular and graphical representations to present the reader an enriched and meaningful translation of the findings which enables and simplifies the process of comparisons across categories, application areas and studies. Both qualitative and quantitative findings are valid inputs for future application areas within big data software architectures.
Grading of recommendation assessment, development and evaluation (GRADE)
GRADE (Grading of Recommendations, Assessment, Development and Evaluations) [2] framework is a systematic approach with a transparent framework to gather and present evidence and measure the quality of it. The method assesses the likelihood of bias at the outcome and is widely adopted by ensuring a transparent link between the evidence and recommendations. The results of application of the GRADE methodology is presented in Section 4.4 for research question RQ4.
Results
Overview of the reviewed studies
The selected 43 primary studies are briefly summarized below:
-
Study 1: This article proposes a five-level of fusion model, in order to process the big datasets with complex magnitudes. Hadoop Processing Server is used. A four-layered network architecture is presented.
-
Study 2: presents AsterixDB, a Big Data Management System. Its target application areas can be listed as web data warehousing, social data storage and analysis, etc. It implements a flexible NoSQL style data model and transaction support similar to that of a NoSQL store.
-
Study 3: A Big Data architecture for construction waste analytics is proposed. A graph database (Neo4J) and Spark is employed. Building Information Modelling (BIM) is investigated for possible extensions.
-
Study 4: In order to design and deploy the scientific applications into the cloud in an agile way, the Scientific Platform for the Cloud (SPC) is developed. The platform embodies a web interface, job scheduling, real-time monitoring etc. Population Genetics, Geophysics, Turbulence Physics, DNA analysis, and Big Data can be listed among the application domains.
-
Study 5: The software architecture presented in this paper is developed to support gathering of IoT sensor-based data in a cloud-based system. The use case is the SMARTCAMPUS project.
-
Study 6: A scalable workflow-based cloud platform is implemented based on Hadoop, Spark, Cassandra, Docker, and R. High performance and productivity is aimed. Data storage and management, data mining and machine learning capabilities are involved.
-
Study 7: WaaS is a standard and service platform architecture for big data. Four service layers implements four components accordingly.
-
Study 8: The study describes the architecture-centric agile big data analytics which is a methodology that combines big data software architecture analysis and design together with agile practices.
-
Study 9: The system architecture of the City Data and Analytics Platform is introduced in this paper. A smart city testbed, SmartSantander, is implemented based on this architecture.
-
Study 10: This paper discusses how to design big data system architectures using architectural tactics considering the design tradeoffs. A healthcare informatics use case is illustrated.
-
Study 11: Private cloud computing platform which is developed for the China Centre for Resources Satellite Data and Application (CCRSDA) and its architectural design is discussed in this paper.
-
Study 12: Semantic-based heterogeneous multimedia retrieval architecture is described in this paper. A NoSQL-based approach to process multimedia data in distributed in parallel and a map-reduce based retrieval algorithm are employed.
-
Study 13: A cloud computing-based system architecture is presented for implementation of a production tracking and scheduling system. A prototype system is implemented and validated in terms of its efficiency.
-
Study 14: A distributed system architecture for text-based social data (Twitter, YouTube, The New York Times etc) is introduced in this paper. HDFS, Map-reduce, and message service analysis are utilized to analyze reputation, social trends, and customer reactions.
-
Study 15: The Alexandria provides a framework and platform for big-data analytics and visualisations mainly for text-based social media data. REST-based service APIs are heavily used within the system architecture.
-
Study 16: Software architectures for Web Observatories are discussed in this paper, for processing real time web streams.
-
Study 17: A generic system architecture is proposed in this paper, which focuses on running big data workflows in the cloud. Big data workflows are investigated in Amazon EC2, FutureGrid Eucalyptus and OpenStack clouds.
-
Study 18: Big Data and data warehousing architectures and design are discussed in this book for the next-generation data warehouse.
-
Study 19: A general system architecture for big data analytics is proposed in this paper, focusing on manufacturing industries.
-
Study 20: This paper discusses the big data with the concept of e-learning and academic environment. A three-step system architecture presented based on a Cloud environment. Graphical Gephi tool is used for analyzing unstructured data.
-
Study 21: An agent oriented architecture is presented in this paper and the proposed for the IoT domain.
-
Study 22: CityWatch framework, which is designed for data sensing and dissemination by using the data collected from Dublin. Two prototype applications are implemented.
-
Study 23: This paper discusses real time big data application architecture challenges. Initial implementation is Hadoop-based which is later replaced with a custom in-memory processing engine.
-
Study 24: This paper focuses on the analysis of the data produced by camera sensors for intruder detection and construction of barrier. A three-layered big data analytics architecture is designed for the study.
-
Study 25: A Big Data architecture system design is introduced in this paper for global financial institutions. Hadoop and no-SQL are applied within the architecture, besides the architecture complies with the data integration, transmission and process orchestration requirements of the application domain.
-
Study 26: A cloud architecture for healthcare is proposed in this paper. In order to use heterogenous devices as data sources, cloud middleware is utilized. Besides different healthcare platforms are integrated via the cloud middleware. The paper also mentions the security and management concerns and emphasizes the importance of the standardized interfaces for the integration with medical devices.
-
Study 27: The paper discusses the social CRM by means of architectural perspectives using five layers.
-
Study 28: In this paper, a technology independent reference architecture is proposed for big data systems. Real use cases are investigated and implementation technologies and products are classified.
-
Study 29: Within the domain of educational technology, based on the Experience API specification, a big data software architecture is introduced in this paper. The data generated as a result of the learning activities of a course is used for the data analytics.
-
Study 30: A big data analytical architecture for a remote sensing satellite application is described in this paper. The data gathered from an earth observatory system is analysed in real time and stored using Hadoop.
-
Study 31: A novel mobile-based end-to-end architecture is described in this study, for the healthcare domain. The architecture is specialized for live monitoring and visualization of life-long diseases. The architecture is based on web services and SOA and a supporting Cloud infrastructure.
-
Study 32: This paper proposes a two-layered cloud architecture for real-time public opinion monitoring model.
-
Study 33: Based on a search cluster for data indexing and query, a cloud service architecture is introduced in this paper. The architecture has the capability to integrate with Hadoop and Spark. REST APIs are employed for access.
-
Study 34: An analytical big data framework is presented in this paper for the smart grid domain. EU funded project BIG and the German funded project PEC are the case studies.
-
Study 35: A big data application architecture for smart cities is implemented within this study. Identify and responding to anomalous and hazardous events in real time is the main goal of the designed architecture. Sensor data is used and sequential learning algorithms are adopted.
-
Study 36: The architecture presented within this paper is for both offline and real time processing and applied for the recommender systems.
-
Study 37: A cloud based big data software application architecture is presented in this paper. The target application domain is research/science. Open source software paradigm is emphasised.
-
Study 38: A real time data-analytics-as-service architecture with RESTful web services is presented in this paper. The architectural challenges are discussed by means of big data processing frameworks, reliability, real time performance and accuracy.
-
Study 39: In this paper, Banian system’s 3-layer system architecture is discussed. The layers are listed as follows: storage, scheduling, application. The results are compared with Hive.
-
Study 40: A novel architecture of big data for assessing the city traffic state is proposed in this paper. A real time, highly scalable system is among the architectural goals. The implementation is based on Hadoop and Spark. Various clustering methodologies like DBSCAN, K-Means, and Fuzzy C-Means are implemented.
-
Study 41: Embodying the big data analytics and service oriented patterns, a big data based analytics system architecture is presented in this paper. The availability and accessibility are the main architectural goals.
-
Study 42: The Cloud Grid (CG) is discussed in in this study for the cloud-based power system operations within the smart grid domain. CG covers the concepts of internet of things (IoTs) together with service-oriented cloud computing and big data analytics. Besides, the architectural constraints related to high performance computing and smart grid are covered within the capabilities of the CG.
-
Study 43: The complex event processing framework H2O is presented in this study. The framework has the capability of supporting the queries over realtime data which are hybrid online and on-demand.
Figure 2 presents the number of selected published 43 papers per year.

Year-wise distribution of primary stuides. * One study that is reviewed in 2016, published in 2017 is included among the publication list.
Table 4 presents the publication channel, publisher and the type of the selected primary studies as an overview. It can be derived from Table 4 that the selected primary studies mostly published by IEEE, Elsevier and ACM that are accepted as highly ranked publication sources. While “Conference on Quality of Software Architectures.” and “SIGMOD International Conference on Management of Data” are significant conferences, “Network and Computer Applications” and “VLDB Endowment” are remarkable journals for the software engineering domain. Besides, it can be indicated that the publication channels that have high impact in the domains other than software engineering are raising the number of papers with emphasis on big data system architectures within their publications. “Renewable and Sustainable Energy”, “Journal of Cleaner Production” and “Journal of selected topics in applied earth observations and remote sensing” can be listed among the remarkable publication changes from other domains.
Research methods
Research method has a critical role within the empirical studies. In order to converge valid and reliable outcomes, clear cut research methodologies should be applied and reported in the selected primary studies. The types of the research methods can be listed as “Case Study” (in depth investigation with a real life context), “Experiment” (scientific procedure to test a hypothesis) and “Short Example”. It can be derived from Table 5 that there is not a tendency towards a research method, considering the fact that the gap between the percentages of the methodologies is not wide. Nevertheless, experimentation is used more often comparing to case studies and short examples to evaluate the system architectures.
Methodological quality
We evaluated the selected primary studies quality using 4 dimensions of quality which are the quality of reporting (Fig. 3), rigor (Fig. 4), relevance (Fig. 5) and credibility (Fig. 6). The questions are grouped as follows: Q1, Q2 and Q3 assess the quality of reporting, while Q4, Q5 and Q6 focus on the rigor. Q7 and Q8 are for assessing credibility, and finally Q9 and Q10 search for relevance. The overall quality checklist results can be found in Appendix 3.

Quality of reporting of the primary studies

Quality of reporting of the primary studies Rigor quality of the primary studies

Relevance quality of the primary studies

Credibility of evidence of the primary studies
The trustworthiness of the primary studies were assessed in the context of rigor. The distribution of the quality scores of the primary studies from the dimension of rigor is presented in Fig. 4. We observe that the quality of rigor of the primary studies scored around the average values. While none of the papers scored below 0.5, the top scored papers are less than 10%. 30% of the studies scored 1 and similarly, the primary studies scored 1.5 are marginally above then 30%. The overall rigor quality appears as average.
The third quality dimension to report is relevance, which is illustrated in Fig. 5. As it can be inferred from Fig. 5, the primary studies are quite relevant to their research questions. About 50% of the studies scored the highest relevance score (i.e. 2), whereas the remaining studies mostly scored around 1–1.5 and only a few studies had a very low score. Therefore, we conclude that the selected primary studies are of high quality relevance.
The credibility quality dimension is summarized in Fig. 6. The studies mostly have slightly below average credibility of evidence. Around 50% of the studies achieved score 1, which we considered fair, and around 30% scored 0.5 indicating a poor quality of credibility. We therefore conclude that the studies barely discuss major conclusions, and poorly list positive and negative findings.
The overall quality scores are shown in Fig. 7, incorporating the quality scores for quality of reporting, relevance, rigour and credibility of evidence. Around 70% of the studies are above average quality (i.e. with a score greater than 4.5). 11% of the papers is in the category of poor quality (< 5) and 29% of the papers have high quality scores (> 7).

Overall quality of primary studies
The distribution of the quality attributes per domain is presented in Fig. 8:

Quality attribute distribution for all domains
Systems investigated
In this section, we present the results which are extracted from 43 selected primary studies in order to answer the research questions.
RQ.1: in which domains is big data software architectures applied?
After screening the selected 43 primary studies, we extracted seven target domains and other domains that have less number of occurrence within the primary studies. The main domains can be listed as follows: Social Media, Smart Cities, Healthcare, Industrial Automation, Scientific Platforms, Aerospace and Aviation, and Financial Services (See Fig. 9).

Domain distribution of primary studies
Table 6 shows the domain categories and their subcategories. For the smart cities domain, the subcategories are smart grid, surveillance system, traffic state assessment, smart city experiment testbed, network security and wind energy. Under the smart grid category, study 34 discusses a smart home cloud-based system for analyzing energy consumption and power quality, while study 42 describes a power system with a cloud-based infrastructure. Within the surveillance systems subcategory, study 24 presents a barrier coverage and intruder detection system, and study 18 introduces a system to track potential threats in the perimeters and border areas. Study 40 presents a cloud-based real-time traffic state assessment system. For the smart city experiment testbed, studies 5, 9, 22 discuss system infrastructures that analyze real-time and historical data from the perspectives of parking occupation, heating and traffic regulation. Study 35 is listed under the network security subcategory for smart pipeline monitoring system. Under the sub-category of wind energy, study 18 discusses a system which uses climate data to predict the most optimal usage of wind energy.
The category of social media consists of the following subcategories: public opinion monitoring, query suggestion and spelling correction, reference architectures of social media systems, web observatories, travel advising, semantic-based heterogenous multimedia retrieval, web data warehousing, social data storage and analytics, social network analysis. Studies 15 and 32 are listed under the public opinion monitoring subcategory which covers exploration and visualization of social media data in connection with a given domain. Study 23 falls under the sub-category of query suggestion and spelling correction and describes the architecture behind Twitter’s real-time related querying service. In study 28, a technology independent big data system reference architecture is presented within the social media domain. Web observatories are introduced in study 16 where gathering, storing and analyzing the data at web scale is the main focus. To monitor and troubleshoot a travel advising system, a big data architecture is defined in study 8. Semantic-based heterogenous multimedia retrieval domain subcategory appears in study 12, in which a big data system is utilized for acquisition and analysis of data from specific websites such as Flickr, Youtube and Wikipedia. Study 2 includes the web data warehousing, social data storage and analytics subdomain. It covers cell phone event analytics, tweet analytics, behavioral data analysis of information streams about events. Study 14 is applied on social network analysis sub-domain, presenting a system that processes the social data in real time.
The industrial applications domain includes 5 subcategories which are environmental sustainability, production tracking and scheduling, manufacturing, automotive and electric power. Study 41 discusses big data analytics for product lifecycle and cleaner manufacturing. Study 3 targets construction waste analytics. Both are listed in the subdomain environmental sustainability. Production tracking and scheduling subdomain appears in the study 13, discussing a system for capturing and analysing the remote production data in terms of tracking and intelligent optimisation. Within the subdomain manufacturing, study 19 covers a system that makes event-based predictions of manufacturing process. Study 17 is presented under the automotive subdomain, introducing a system for analyzing driving competency from the vehicle data. Electric power subdomain includes study 6, discussing a big data system that uses historical data to predict short term electricity load in a certain area.
Four subdomain categories appear in healthcare domain, listed as follows: brain and health monitoring, improving healthcare quality and costs, patient monitoring and interconnection of healthcare platforms. Studies 1, 7, 31 are included within the brain and health monitoring subcategory. Study 1 analyses heart rate, ECG and body temperature. Study 7 analyses brain health and mental disorders. Likewise, study 31 monitors and visualizes epileptic disease-related data. Improvement of healthcare quality and costs subdomain category appears in the studies 18 and 10, involving complex data processing, clinical quality measure analytics and proactive care management analysis. Study 21 is applied on patient monitoring subcategory which covers a system for the analysis of the emergency situations and medical records. In study 26, interconnection of the healthcare platforms is discussed and an overview of the required cloud computing middleware services and standardized interfaces for the integration with medical devices is presented.
The domain scientific platforms involves four subdomain categories as follows: digital libraries for scientific data management, scientific platforms for the cloud, e-learning and learning analytics. Study 37 is listed under digital libraries for scientific data management subdomain as it reports a use-and-reuse-driven big data management infrastructure. Within the scientific platform for the cloud subdomain, study 4 introduces a framework to support rapid design and deployment of scientific applications to cloud. The learning analytics domain appears in study 29, presenting a system to predict the learner’s performance, discovering the real learning paths and extracting the learner’s behavior patterns. Study 20 is included in the e-learning domain and analyses the influence of big data technologies on the academic platforms.
The sixth domain category is earth observation and aviation, which has two subdomains: earth observation, aviation maintenance and optimization. Studies 1, 11, 30 are within the earth observation domain subcategory analyzing earth data, downloading, processing and viewing satellite images. In [12] a cloud platform is presented with a processing chain model for satellite images with the focus of providing interactive real time services. A real time big data analytical architecture is proposed in [14] for remote sensing satellite application. Besides in [14], a multidimensional big data fusion approach is implemented with a big data architecture and tested with satellite data. Aviation maintenance and optimization domain appears in study 10 and focuses on diagnosing faults in real time, optimizing fuel consumption and predicting maintenance need.
The last target domain category is Financial Services and it is applied into subcategories that are banking with study 25 focusing on cost reduction, scalability and availability of the infrastructures and social customer relationship management with study 27 which presents an architecture consisting of five layers aiming the understanding and implementation of social CRM aspects and dependencies.
Other subdomains which are not listed under any target domain are ambient intelligence (21), recommendation systems (36), anomaly detection (38), trace analyzer (33) and query engine (43). An online and on demand quarry engine implementing complex event processing to cover a variety of data for querying in real time is discussed in 43 with the target domains e-commerce and energy. Insights about how the backend systems work or for the cloud monitoring systems, traces are analyzed in 33 which can be applicable to any domain. Study 38 targets creating common and reusable services in order to make real time analytics as a service for an anomaly detection system. Modelling lambda architecture as a multi agent heterogenous system, a recommendation system is discussed in 36. Another multi agent architecture is proposed within the direction of internet of things and a case study on ambient intelligence is applied for a smart house in 21.
RQ.1.1: who are the stakeholders?
Answering this research question, we aim to identify the stakeholders that are targeted in different application domains. Various stakeholders are mentioned within in the papers from the following application domains: Industrial Applications, Smart Cities, Social Media, Scientific Platforms. Managers appear frequently as a stakeholder in the studies from the industrial application domain. Whereas for the smart cities domain, depending on the subdomain, the stakeholders significantly differ. In Table 4, a subset of the application domains and the corresponding stakeholders are listed: Table 7
RQ.2: what is the motivation for adopting big data architectures?
Here, we aimed to identify the motivation for adopting big data architectures within the papers examined:
Supporting analytics processes
Effective processing and management of massive volumes of data to support data analytics processes is one of the main motivations behind adopting a big data architecture. The input for the big data analytics processes often involves multimedia data, including text, sensor-born data, or music/video streams in order to carry out comparative analysis and identify the emerging patterns and associated relationships in the various domains of application. Big data architectures, infrastructures and tools enable the systems to provide with better decision support.
Improving efficiency
Another main motivation for adopting big data architectures is efficiently processing massive volume of heterogenous data with flexible, semi-structured data models and wide range of query sizes while ensuring the fault tolerance of the deployed solution. Monitoring massive information efficiently is also emphasized in the selected primary studies. Execution of join queries on different big data platforms and different big datasets efficiently and interactive querying in timely fashion are also among the goals for adopting big data architectures.
Improving real-time data processing capability
The third main reason behind applying big data systems is to gain the ability to deal with the unprecedented speed of real time data generation and the associated needs of processing it. The Internet of Things is a driver for the intensive deployment of sensors, which subsequently generate data streams that are gathered, monitored and processed via big data tools for making event based predictions, querying (complex and ad-hoc) and complex event processing. The big data architecture shall be effectively meeting the latency requirements in such cases.
Reduce development costs
Another main reason is to reduce the costs for system deployment or operation. For example, in the financial sector, market conditions change abruptly, which triggers the urge of processing high volumes of data in short time. Similarly in [13], to improve the user experience, an effective and economical architecture is designed considering time and storage costs. Minimizing costs of both sensors and data storage are at the main focus in [15]. Reducing the development cost of analytical services for citizens and decision makers, efficient use of natural and manmade resources is targeted in [16] and mining big data is used as a valuable source to achieve these targets.
Enable new kind of services
Providing new services to support the rapid design and deployment of scientific applications is the primary goal of the scientific platform described in [17]. Service oriented architecture and the semantic web are in the light of this study. The platform adopts software-as-a-service approach and enables the execution, packaging, uploading and configuring of the scientific software applications. In order to support the collection of the data from sensors, in [11] a new kind of big data architecture is defined. This architecture resolves the problems related to data storage, data processing, sensor heterogenity and high throughput and addresses the data-as-a-service requirement of the system with the support of a reception middleware. As another approach, workflow web services with special analysis processes (speech tagging, named entity recognition etc.) are implemented in [10] to support data scientists to rapidly implement data mining applications.
Data management and system orchestration
The last main reason is enabling the system to manage and orchestrate big data sets. In [5], an architecture centric approach is presented to control continuous big data delivery, discussing big data system design and agile analytics development. It focuses on the orchestration of the technologies, prototypes and benchmarks each technology and uses conceptual data modelling method to extend the architecture [4]. presents a system architecture which fosters the system orchestration utilizing REST-based services. The system not only supports data collection, processing and analytics but also enables integration to the other social media analytics systems. The details of the data management concerns for the other studies are listed in Table 8.
RQ.3: what are the existing approaches for software architecture for big data?
Three main approaches are observed for designing the software architectures for big data systems throughout the screening process of the selected primary studies: Adopt a reference architecture, follow an architectural design methodology and use a reference model. The first approach is adopting a reference architecture. In studies 8, 34 and 36, lambda architecture appears as the reference architecture which enables efficient real-time and historical analytics via a robust framework. As another approach, Prometheus methodology which supports the design of multi-agent systems based on plans, goals, behaviours and other aspects, is used in study 25. In study 38, the OAIS reference model is followed to design the software architecture. The OAIS Reference Model provides a conceptual framework for service oriented architectures. Finally, study 28, differentiated replication research methodology is applied to design the reference architecture. Most papers did not explicitly report on the software architecture approach they adopted. This does not imply that such an approach was not used. It was not reported, as many of these studies were not addressing the software architecture community.
RQ.3.1: What are the adopted architectural models/viewpoints?
The adopted architectural viewpoints (Fig. 10) are the decomposition (presents elements, relations and topology assigning responsibilities to modules), flowchart (displays tasks in a network diagram style) and the deployment (aspects of the system ready to go in live) viewpoints. Eight studies do not include a viewpoint. The decomposition viewpoint is the most applied among the appeared viewpoints. Note that 90% of the architectures that adopt the decomposition viewpoint are layered architectures.

Adopted architectural viewpoints in primary studies
RQ.3.2: What are the adopted architectural tactics/patterns?
There are five architectural patterns reported within the selected primary studies which are listed as follows: Layered (data is forwarded from one level of processing to another in a defined order), cloud based (architectural elements are in cloud), hybrid (combination of different architectural patterns) and multi-agent (a container/component architecture, containers are the environment and components are the agents) (Fig. 11).

Adopted architectural patterns in primary studies
In [18], the system architecture proposed for cleaner manufacturing and maintenance is composed of 4 layers that are data layer (storing big data), method layer (data mining and other methods), result layer (results and knowledge sets) and application layer (uses the results from result layer to achieve the business requirements). In [19], the traditional 3 layered architecture of the financial systems was adopted: front office (interaction with external entities, data acquisition and data integrity check), middle office (data processing), back office (aggregation and validation). While at least a 3-layered approach is applied for most of the application domains and two layers with processing and application layer driving the results via aggregation and validation is consistent for all domains, the layers on top are adopted depending on the application domain.
For web-based systems, lambda architecture is implemented in [4] with the batch (non-relational) and streaming layer (real-time data) completely isolated, scalable and fault tolerant. For machine to machine communication, a 4 layer architecture is presented with the service (business rules, tasks, reports), processing (Hadoop, HDFS, MapR), communication (m2m, binary/text I/O) and data collection layers. The layered architecture of the AsterixDB (an open source big data management system) is shown in [2]. Hyracs layer and Algebrics Algebra layer are layers that are represented within the software stack. Hyraces layer accepts and manages the parallel data computations (processing jobs and output partitions). Algebrics layer which is data model neutral and supports high level data languages, aims to process queries. Banian system architecture which is described in [20] consists of 3 layers which are storage, scheduling and execution and application layer and the system provides better scalability and concurrency. The architecture proposed in [15] is for intruder detection in wireless sensor networks. Three layered big data analytics architecture is designed: wireless sensor layer (wireless sensors are deployed), big data layer (responsible for streaming, data processing, analysis and identifying the intruders) and cloud layer (storing and visualizing the analyzed data).
Cloud based architectures are also frequently observed among the selected primary studies. In [2], a scalable and productive workflow based cloud platform for big data analytics is discussed. The architecture is based on the open source cloud platform ClowdFlows. Model view controller (MVC) architectural pattern is applied. The main components are data storage, data analytics and prediction and data visualization which are accessible via a web interface. The architecture of [17] uses the cloud environment (Amazon EC2 cloud service) to store the data collected from the sensors and host the middleware. Overall system is composed of sensors, sensor boards, bridge and middleware. Another cloud architecture is used to construct a cloud city traffic state assessment system in [21] with cloud technologies, Hadoop and Spark. Clustering methods such as K-Means, Fuzzy C-Means and DBSCAN are applied to detect the traffic jam. The architecture has 2 high level components which are data storage and data analysis and computation. While data storage is based on Hadoop HDFS and NoSQL, data analysis and computation part utilizes Spark for high speed real time computation. For all of the big data systems applying cloud based architectures, the cloud is used to resolve the scalability problem of the data collection.
In order to provide the users interactive real time processing of the satellite images, a cloud computing platform is introduced for the China Centre for Resources Satellite Data and Application (CCRSDA) in [12]. The platform aims low latency, disk-space customization and remote sensing image processing native support. The architecture consists of application software including image search, image browsing, fusion and filter, web portal containing private file center, data center, app center, route service and work service, virtual user space management, Moosefs, ICE and Zookeeper and virtual machine management (3 service levels, Saas, PaaS and IaaS respectively).
One of the primary studies [22] discusses a multi-agent architecture for real time processing. The lambda architecture is modelled as a heterogeneous multi-agent system in this study as 3 layers (batch, serving and speed layer). The communication among the components within the layers is achieved via agents with message passing. The multi agent approach simplifies the integration.
Service oriented architectures are frequently applied for big data systems. In [23] a cloud service architecture is presented. It has three major layers which are an extension of semantic-wiki, rest api and SolrCloud cluster. The architecture explores a search cluster for indexing and querying. Another system architecture described in [5] is based on a variety of rest-based services for the flexible orchestration of the system capabilities. The architecture includes domain modelling and visualization, orchestration and administration services, indexing and data storage.
Other state of the art approaches
Cybersecurity
Software systems are developed and integrated aligning with a software application architecture and deployed when the system is mature enough satisfying the acceptance criteria for the system release and deployment. If the maturity of the system is measurable, the quality metrics are utilized to assess the performance of the system. While a system is performing, the vulnerabilities rooted in the system architecture, deployment configuration or the network architecture enables an external or internal entity to perform malicious activities. Tracing or pre-detecting the vulnerabilities residing within the system could support the decision process for maintenance, risk analysis, implementation or system extension processes. Not only for the system performance but also for the vulnerability analysis which could directly have an impact on the performance itself, system specific metrics could be selected and defined. However, due to the rapid technological developments, system specific and implementation specific codes, artefacts and configurations and maintenance activities, resulting with the right set of metrics is a challenge.
According to [24] “Resilience – i.e., the ability of a system to withstand adverse events while maintaining an acceptable functionality – is therefore a key property for cyberphysical systems”. Primary approaches to measure the resilience could be model based or metric based. As a metric based approach, resilience indexes are defined to be extracted from system data such as logs and process data as a quantitative general-purpose methodology [24].
Resilience readiness level metrics are proposed in [25], as shown in Table 9 and as a matter of fact, the aspects that the big data systems are related to the readiness levels from the cybersecurity point of view are outlined and discussed.
Another study in the survey format is composed in 2018 which is called “Big Data Meets Cyberphysical Systems” [28], that summarizes the impact of the increasing variety of the cyberphysical systems and the amount of sensor data produced. The study also discusses the cyber attacks targeting such systems. Centroid based clustering and hierarchical clustering are listed as two groups of clustering methods. K-means is an example of the clustering methods and it has the empty clustering problem. For the hierarchical clustering, the clusters are defined based on similarity measures such as distance matrices and the clustering speed and accuracy is higher comparing to the other algorithms like k-means.
Integration is a concern in cyberphysical systems in critical infrastructures due to the computational challenges observed while applying techniques for data confidentiality and privacy protection [34]. Semi or fully autonomous security management could be adapted according to the needs of the application to be implemented. The solutions could have high cost by means of latency, power consumption or management complexity.
Deep learning
Application of deep learning in big data is discussed in [15], stating the challenges as:
-
Estimating the portion/amount of the big data to be used for the deep learning approach
-
Overcoming the gap between test and the training data via having generalized learnt patterns.
-
Determining the criteria that is representative for the data.
-
The interpretation of the complex result.
-
Labeled data is required for good performance.
-
Open questions are:
-
The way to fuse the conflicting data.
-
The effect of enlarged modalities on system performance.
-
The architectural approaches for feature fusion and heterogenous data.
-
Data with high velocity, how to approach the variety of the data distribution with respect to time.
In [19] emotion recognition is achieved via the fusion of the outputs of convolutional neural networks (CNN) and extreme learning machines (ELM) and for final classification SVM is used. The architectural approach could be characterized as hybrid application architecture having CNN and SVM with ELM fusion. Achieving high accuracy with this approach, it is observed that data augmentation improved the accuracy further.
Sentiment analysis
In [29] is analysed based on topics of sensitive information. In order to accomplish the analysis, bidirectional recurrent neural network (BiRNN) and LSTM are combined to form BiLSTM to ensure having context information continuously. The architecture has a layered structure.
The brand authenticity analysis is carried out in [30]. The quality commitments for the tweets are instantly sharing sentiments, sharing complaints, processing complaints and the quality of ingredients. Statistica 13 software is used fort SVM analysis.
RQ.4: What is the strength of evidence of the study?
In order to state the plausibility of the results, within this research question we will be discussing to which extent the audience of this study can rely upon the outcomes. Among the various definitions to address the strength of evidence, for this SLR we selected the Grading of Recommendation Assessment, Development and Evaluation (GRADE). As it can be observed from the Table 10 (adopted from [17]), there four grades which are high, moderate, low and very low to assess the strength of evidence which takes into consideration the quality, consistency, design and directness of the study. Comparing to the observational studies, experimental studies are graded higher by the GRADE system. Among the primary studies in this review, 16 (37%) are experimental. The average quality score of these studies is 6,4 which means that our studies have a moderate strength of evidence based on the design (Table 11).
Most of the primary studies we analyzed do not include explicitly a quality assessment by means of our quality criteria which are rigor, credibility and relevance. Therefore there is a risk of bias implied by the low quality scores.
In terms of quality, from the rigor perspective, we can observe a variety of presentation structure and reporting methods which complicates the comparison of the content. For most of them the aim, scope and context are clearly defined, however for some of them the results are not clearly validated by an empirical study or the outcomes are not quantitatively presented. Besides, throughout many studies, research process is documented explicitly but some of the research questions remained unanswered. Considering credibility, while the studies tend to discuss credibility, validity and reliability, they generally avoid discussing negative findings. The conclusions are quite relating to the purpose of the study, and the results are relevant while not always practical.
Considering the fact that the presentation of the research questions and the results extremely varying from study to study, it is very complicated to analyze the consistency of the outputs of the primary studies. As a result, sensitivity analysis and synthesis of the quantitative results were not feasible.
With respect to directness, the total evidence is moderate. According to Atkins et al., (2004) a directness is the extent to which the people, interventions, and outcome measures are similar to those of interests. The people were experts from academy or industry which are within the area of interest. The outcomes are not restricted for this literature survey. A considerable amount of primary studies answers the research questions and validates the outcome quantitatively.
Assessing all elements of the strength of evidence, the overall grade of the impact of the big data system architectures presented throughout the primary studies is moderate.
Discussion
Various dimensions of improvements are analyzed, implemented and experimented throughout the studies listed in previous chapters. In AsterixDB, the performance of the functions within dataflows are planned to be improved via introducing further parallelism for function evaluation in pipeline.
The performance is measured in the presented big data architectures for construction waste analytics by means of accuracy. Application areas within the internet of thigs field the challenge is scaling the platform, privacy and security both for the data and the system. Assessing the maturity of a big data system and which metrics to measure the maturity is another area to be explored.
Hybrid architectures are not often observed among the primary studies, however could be benefited more as in the application architecture having CNN and SVN for the sentiment analysis. Integration concerns for big data systems within the cyberphysical domain is to be further investigated (Tables 12, 13, 14 and 15).
Threats to validity
In order to have a valid systematic literature survey, we should make sure that the research protocol and the constructed research questions ensure elimination of the publication bias, in which the positive results tend to be presented by the researches. In our study the search is conducted automatically, therefore the search string is also aligned with the target. The keyword list within the search string can result with incompleteness, which can be resolved using an iterative approach to construct the keyword list. Combining the search results in digital libraries with the results from the search engines we achieve a better coverage of the search results. Keyword list is incrementally expanded or shrinked to cover target studies. Considering the irrelevant searches introduced by the inefficient search algorithms of the digital libraries, manual selection criteria are defined.
Modelling the data extraction method is critical to derive the correct results from the selected primary studies to overcome the data extraction bias. The selected papers are screened considering the previously defined research questions to form the initial data extraction model. We iterate through the selected papers by adding and removing the fields to the data extraction model until we eliminate irrelevant results and have enough coverage within the final data extraction model [32].
Conclusion validity
The systematic literature review methodology has a significant control on the primary studies that are derived as an output of the screening process. The data extraction columns are peer reviewed in order to have a common and generic objective for the study. The results are based on a solid mapping to the selected primary studies which is traceable via the data extraction table.
Internal validity
Exclusion criteria that is applied for the selection of the studies has the highest effect on the result. Exclusion criteria is also peer reviewed to ensure the precision and recall.
Construct validity
The goal of the study is analyzing different aspects of the primary studies such as architectural methods/viewpoints, stakeholders, key concerns etc. focusing on the application domain. The outcomes of the analyzed aspects are presented in Section 4 Results.
External validity
The results are applicable for the application domains listed in Section 4. In case of having overlapping key concerns or quality goals, the results can be implemented in other application domains.
Related work
Hu, Han, et al. (2014) in “Toward scalable systems for big data analytics: A technology tutorial.” conducted a literature survey and provided a tutorial on big data analytics platforms to introduce the overall picture about the big data solutions [10]. They introduced a big data technology map which visualizes the exemplary technologies over the past 10 years, relating it with the data value chain that consists of the data generation, data acquisition, data storage and analytics. Alternatively, they present the layered architecture for the big data systems which is decomposed into 3 layers which are infrastructure layer, computing layer and application layer. The study discusses the big data system challenges, data sources, frameworks and their applications. Compared to our study, Hu, Han, et al. (2014) reviewed the technologies mapping to the big data system architectures, while we focused instead on the architectural perspectives and big data application domains.
In the literature review of Tan, et al. (2015), the focus is on the big data architectures for pervasive healthcare systems that aims to deliver healthcare services to patients anywhere and anytime, including data collection via mobile devices and sensor network [1]. Besides it discusses the relationship between the research directions and the compiled big data architecture. While our study screens various application domains, the literature review of Tan, et al. (2015) discusses the big data architectures based on a single application domain. Aligned with our study, the data interoperability, security and privacy are among the key concerns for the big data system architectures in healthcare domain.
In “How ‘big data’ can make big impact: Findings from a systematic review and a longitudinal case study”, Jamba et al. present a framework which analyses the big data from the definition perspective [4]. Besides, presenting a general taxonomy, the paper also enables the reader to understand the big data systems and how business value is derived out of it. The study is a comprehensive literature review which does not discuss the big data system architectures in depth, rather focuses on the business and practical aspects of the big data systems.
“A general perspective of Big Data: applications, tools, challenges and trends” is another study presenting the main trends, technical domains and tools for big data systems and summarizes the state of art in big data [12]. The study screened 457 papers and classifies them into 6 categories which are capture, store, search, share, analysis and visualization and mentions analysis as the most important category. Besides the widely applied frameworks are listed as Hodoop, Mahout, Storm, Spark, S4, Drill, MapReduce, Dryad, MOA, SpagoBI and D3.js.
The study “Big Data and virtualization for manufacturing cyber-physical systems: A survey of current status and future outlook” was authored by Babiceanu et al. Manufacturing cyber physical systems are monitored by means of simulation and data processing simultaneously with the actual physical world operations. The study reviews the application of the big data analytics, virtualization and cloud based services for planning and control of the manufacturing operations [33].
Previous work did not review big data software architectures with a methodological approach such as systematic literature review as we provided within this study. The data extraction methodology, elimination criteria and the research questions on the domain analysis and architectural aspects such as patterns, viewpoints, quality attribute are uniquely represented for the big data software architecture field within our study.
Conclusions
In this paper, we have presented the results of a systematic literature survey on software architectures for big data systems. We screened the application domains that the big data software architectures were applied, and as a target, identified the current domains, architectural concerns, aspects and future research and application areas There has been no previous systematic literature survey study performed yet on big data system architectures for this purpose in the known literature. The systematic literature survey is carried out covering the published literature since 2013. Starting with a corpus of 622 papers from the searching literature, we narrowed them down to 43 primary studies to address our research questions.
We have analyzed the current big data software architectures for various domains and presented the results to support the researchers and readers in terms of having a consolidated information and identifying the future research areas. We can conclude that big data software architectures are applied in various application domains. We identified recurring common motivations for adopting big data software architectures, such as supporting analytics process, improving efficiency, improving real-time data processing, reducing development costs and enabling new kind of services, including collaborative work.
As a result of the final set of primary studies quality attribute have a clear impact on the big data software architectures. The business constraints vary for each application domain, therefore targeting a big data software application for a specific application domain requires tailoring of the generic reference architectures to a domain specific reference architecture to better support derivation of the application architectures. Among the primary studies, none of the reference architectures is indicated or suggested for a specific application domain. Considering the fact that a detailed application architecture is often missing in the primary studies, an overall evaluation of the architecture is not feasible for them.
Having a uniform platform, flexibility, sparsity of the data, hiding the details of the sensor nodes and sensor heterogeneity, dynamic decision making, common service interfaces and being accessible to non-technical users are listed among the concerns that are associated with the architectures for the application domains of our selected primary studies. The architectural concerns derive the quality attributes such as safety, low latency, reliability, reuse, high performance, availability, resilience and scalability. Gathering the stakeholders’ needs and applying the appropriate architectural design methodology which can be based on a reference architecture, architectural styles or patterns such as layered, cloud based, multi-agent or service oriented and architectural viewpoints like deployment, flowchart or decomposition can be utilized. The technologies to be adopted and the integration concerns at the system and system of systems level are also to be defined while deriving the application architecture from the described big data system software architecture based on an application domain.
In this study, we focused on the most relevant primary studies in the known literature of the big data software architecture domain. We analyzed the studies in terms of key concerns, application domains, stakeholders, motivations, architectural approaches, models viewpoints and discussed the strength of evidence of the and threads to validity of the results. The reliability and credibility of data and having low latency and providing real time information is the key for smart cities, while in social media efficiency, load balancing and user friendliness is critical. Similarly, scientific applications are expected to be scalable, flexible and user friendly. Within the aerospace and aviation domain, real time and offline decision making is expected. Depending on the application domain, the stakeholders vary, such as for industrial applications, designers, managers, suppliers, manufacturers and customers are among the stakeholders while for scientific platforms the stakeholders are the system administrators and engineers. The main motivation is scalability and high performance where maintainability and deployment are given less emphasis. From the architectural approach point of view, layered, cloud based, service oriented and multi-agent architectures are applied to the big data systems.
As a future work, we will analyze big data software architectures of different use cases from various application domains against our results and discuss identified challenges and possible enhancements.
Availability of data and materials
All the material is accessible (please see references and the primary studies sections).
Abbreviations
- ACM:
-
Association for Computing Machinery
- Amazon EC2:
-
Amazon Elastic Compute Cloud
- ASAR:
-
Advanced Synthetic Apertures Radar- earth data
- AsterixDB:
-
Scalable, open source Big Data Management System
- BigMM:
-
International COnference on Multimedia Big Data
- BIM:
-
Business Informatics Management
- CCRSDA:
-
China Center for Resources Satellite Data and Application
- COMM:
-
Communications
- CPU:
-
Central Processing Unit
- CRM:
-
Customer Relationship Management
- DBSCAN:
-
Density-based spatial clustering of applications with noise
- CG:
-
Cloud Grid
- DNA:
-
Deoxyribonucleic acid
- ECG:
-
Elektrocardiogram
- FiCloud:
-
Future internet of things cloud
- GB:
-
Giga byte
- GIS:
-
Geographical information systems
- GRADE:
-
Grading of Recommendations Assessment, Development and Evaluation
- HDFS:
-
Hadoop Distributed File System
- H2O:
-
Open source, distributed in-memory machine learning platform
- ICBDA:
-
International conference on big data analytics
- IAT:
-
Intelligent Agent Technologies
- IEEE:
-
International ELectrics and Electronics
- MapR:
-
Map Reduce
- MVC:
-
Model View Controller
- Neo4J:
-
Graph database management system developed by Neo4j Inc.
- NoSQL:
-
Non SQL, non relational
- OAIS:
-
Open Archival Information System
- Q1, Q2,:
-
Question 1, Question 2,
- RAM:
-
Rapid Access Memory
- REST:
-
Representational State Transfer
- RQ:
-
Research Question
- SCC:
-
Services Computing
- SIGMOD:
-
Special Interest Group on Management of Data
- SLR:
-
Systematic Literature Review
- SPC:
-
Statistical process control
- SQL:
-
Structural Query Language
- TECS:
-
Transactions on Embedded Computing Systems
- VLDB:
-
Very Large Databases
- WaaS:
-
Wide area application services
- WI:
-
Web Intelligence
References
Gorton I, Klein J. Distribution, data, deployment: software architecture convergence in big data systems. IEEE Softw. 2014;32(3):78–85.
Atkins D, Best D, Briss PA, Eccles M, Falck-Ytter Y, Flottorp S, et al. Grading quality of evidence and strength of recommendations. BMJ. 2004;328(7454):1490. https://doi.org/10.1136/bmj.328.7454.1490.
Angelow S, Grefen P, Greefhorst D. A classification of software reference architectures: analyzing their success and effectiveness. In: Joint working IEEE/IFIP conference on Software Architecture & European Conference on software architecture; 2009. p. 141–50.
Gölzer P, Cato P, Amberg M. Data Processing Re- quirements of Industry 4.0 - Use Cases for Big Data Ap- plications. In: Proceedings of the 23th European Confer- ence on Information Systems (ECIS), paper 61; 2015.
Tan et al., 2015 C. Tan, L. Sun, K. Liu Big data architecture for pervasive healthcare: a literature review Proceedings of the Twenty-Third European Conference on Information Systems, Münster, Germany, 2015:26–29.
Perry DE, Wolf AL. Foundations for the study of software architecture. ACM SIGSOFT Software Eng Notes. 1992;17(4):40–52.
Rodríguez-Mazahua L, Rodríguez-Enríquez CA, Sánchez-Cervantes JL, Cervantes J, García-Alcaraz JL, Alor-Hernández G. A general perspective of big data: applications, tools, challenges and trends. J Supercomput. 2016;72(8):3073–113.
Hu H, et al. Toward scalable systems for big data analytics: a technology tutorial. IEEE Access. 2014;2:652–87.
Jin X, Wah BW, Cheng X, Wang Y. Significance and challenges of big data research. Big Data Res. 2015;2(2):59–64.
Garlan D, Shaw M. An introduction to software architecture. In: Advances in software engineering and knowledge engineering, 1.3.4; 1993.
Bachmann F, Bass L, Klein M. “Architectural tactics: a step toward methodical architectural design”, technical report CMU/SEI-2003-TR-004, Pittsburgh, PA; 2003.
Kitchenham B, Charters S. Guidelines for performing systematic literature reviews in software engineeringTechnical Report, EBSE; 2007.
Kitchenham B, Budgen D, Brereton OP, Turner M, Bailey J, Linkman S. Systematic literature reviews in software engineering - a systematic literature review. Inf Softw Technol. 2009;51(1):7–15. https://doi.org/10.1016/j.infsof.2008.09.009.
Rathore M, M U, Paul A, Ahmad A, Chen BW, Huang B, et al. Real-time big data analytical architecture for remote sensing application. IEEE J Selected Topics Appl Earth Observ Remote Sensing. 2015;8(10):4610–21.
Gheisari M, Wang G, Bhuiyan MZA. A survey on deep learning in big data. In: 2017 IEEE international conference on computational science and engineering (CSE) and IEEE international conference on embedded and ubiquitous computing (EUC), vol. 2: IEEE; 2017.
Strohbach M, Ziekow H, Gazis V, Akiva N. Towards a big data analytics framework for IoT and smart city applications. In: Modeling and processing for next-generation big-data technologies. Cham: Springer; 2015. p. 257–82.
Clements P, Garlan D, Bass L, Stafford J, Nord R, Ivers J, et al. Documenting software architectures: views and beyond: Pearson Education; 2002.
Zhang Y, Ren S, Liu Y, Si S. A big data analytics architecture for cleaner manufacturing and maintenance processes of complex products. J Clean Prod. 2017;142:626–41.
Hossain MS, Muhammad G. Emotion recognition using deep learning approach from audio–visual emotional big data. Inf Fusion. 2019;49:69–78.
Xu T, Wang D, Liu G. Banian: a cross-platform interactive query system for structured big data. Tsinghua Sci Technol. 2015;20(1):62–71.
Yan YZ, Liu RH, Yang CT, Chen ST. Cloud city traffic state assessment system using a novel architecture of big data. In: International conference on cloud computing and big data (CCBD); 2015. p. 252–9. IEEE.
Twardowski B, Ryzko D. Multi-agent architecture for real-time big data processing. In: 2014 IEEE/WIC/ACM international joint conferences on web intelligence (WI) and intelligent agent technologies (IAT), vol. 3: IEEE; 2014, August. p. 333–7.
Singh S, Liu Y. A cloud service architecture for analyzing big monitoring data. Tsinghua Sci Technol. 2016;21(1):55–70.
Murino G, Armando A, Tacchella A. Resilience of cyber-physical systems: an experimental appraisal of quantitative measures. In: 2019 11th international conference on cyber conflict (CyCon), vol. 900: IEEE; 2019.
Rubio JE, Roman R, Lopez J. Analysis of cybersecurity threats in industry 4.0: the case of intrusion detection. In: International conference on critical information infrastructures security. Cham: Springer; 2017. p. 119–30.
Grubel BC, Reid DSD. U.S. patent no. 9,712,551. Washington, DC: U.S. Patent and Trademark Office; 2017.
Li Y, et al. Intelligent cryptography approach for secure distributed big data storage in cloud computing. Inf Sci. 2017;387:103–15.
Atat R, et al. Big data meet cyber-physical systems: a panoramic survey. IEEE Access. 2018;6:73603–36.
Xu G, et al. Sensitive information topics-based sentiment analysis method for big data. IEEE Access. 2019;7:96177–90.
Shirdastian H, Laroche M, Richard M-O. Using big data analytics to study brand authenticity sentiments: the case of Starbucks on twitter. Int J Inf Manag. 2019;48:291–307.
Wamba SF, Akter S, Edwards A, Chopin G, Gnanzou D. How ‘big data’can make big impact: findings from a systematic review and a longitudinal case study. Int J Prod Econ. 2015;165:234–46.
Zhang H, Babar MA, Tell P. Identifying relevant studies in software engineering. Inf Softw Technol. 2011;53(6):625–37. https://doi.org/10.1016/j.infsof.2010.12.010.
Babiceanu RF, Seker R. Big data and virtualization for manufacturing cyber-physical systems: a survey of the current status and future outlook. Comput Ind. 2016;81:128–37.
Lee J, Bagheri B, Kao H-A. A cyber-physical systems architecture for industry 4.0-based manufacturing systems. Manuf Lett. 2015;3:18–23.
Acknowledgements
All authors would like to thank to the reviewers for the valuable comments.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
All authors have contributed equally to finish this paper. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1
Appendix 2
List of primary studies
-
1.
Ahmad, A., Paul, A., Rathore, M., Chang, H, “An efficient multidimensional big data fusion approach in machine-to-machine communication”, ACM Transactions on Embedded Computing Systems, 2016, (TECS), 15(2), 39.
-
2.
Alsubaiee, S., Altowim, Y., Altwaijry, H., Behm, A., Borkar, V., Bu, Y., Gabrielova, E, “AsterixDB: A scalable, open source BDMS” Proceedings of the VLDB Endowment, 2014, 7(14), 1905–1916.
-
3.
Bilal, M, Oyedele, L, O, Akinade, O, O, Ajayi, S, O, Alaka, H, A, Owolabi, H, A., Bello, S, “Big data architecture for construction waste analytics (CWA): A conceptual framework”, Journal of Building Engineering, 6, 2016, 144–156
-
4.
Brewer, W., Scott, W., Sanford, J, “An Integrated Cloud Platform for Rapid Interface Generation, Job Scheduling, Monitoring, Plotting, and Case Management of Scientific Applications”, 2015, International Conference on Cloud Computing Research and Innovation (ICCCRI), 2015, pp. 156–165, IEEE.
-
5.
Cecchinel, C., Jimenez, M., Mosser, S., Riveill, M, “An architecture to support the collection of big data in the internet of things”, IEEE World Congress on Services, 2014, pp. 442–449.
-
6.
Chen, C., Yan, Y., Huang, L., Dong, X, “A scalable and productive workflow-based cloud platform for big data analytics”, IEEE International Conference on Big Data Analysis (ICBDA), 2016, pp. 1–5.
-
7.
Chen, J., Ma, J., Zhong, N., Yao, Y., Liu, J., Huang, R., Gao, Y, “WaaS—Wisdom as a service”, Wisdom Web of Things, 2016, pp. 27–46, Springer, Cham.
-
8.
Chen, H, M, Kazman, R, Haziyev, S, “Agile big data analytics for web-based systems: An architecture-centric approach”, IEEE Transactions on Big Data, 2(3), 2016, 234–248.
-
9.
Cheng, B, Longo, S, Cirillo, F, Bauer, M, Kovacs, E. “Building a big data platform for smart cities: Experience and lessons from Santander”, IEEE International Congress on Big Data, 2015, pp. 592–599.
-
10.
Gorton, I, Klein, J, “Distribution, data, deployment: Software architecture convergence in big data systems”, IEEE Software, 2014, 32(3), 78–85.
-
11.
Guo, W, She, B, Zhu, X, “Remote Sensing Image On-Demand Computing Schema for the China ZY-3 Satellite Private Cloud-Computing Platform”, Transactions in GIS, 18, 2014, 53–75.
-
12.
Guo, K, Pan, W, Lu, M, Zhou, X, Ma, J, “An effective and economical architecture for semantic-based heterogeneous multimedia big data retrieval”, Journal of Systems and Software, 2015, 102, 207–216.
-
13.
Guo, Z, X, Yang, C, “Development of production tracking and scheduling system: A cloud-based architecture”, International Conference on Cloud Computing and Big Data, 2013, pp. 420–425.
-
14.
Han, Y, Lee, H, Kim, Y, “A real-time knowledge extracting system from social big data using distributed architecture”, Conference on research in adaptive and convergent systems, 2015, pp. 74–79, ACM.
-
15.
Heath, F, F, Hull, R., Khabiri, E., Riemer, M., Sukaviriya, N, Vaculín, R, “Alexandria: extensible framework for rapid exploration of social media”, IEEE International Congress on Big Data, 2015, pp. 483–490, IEEE.
-
16.
Tinati, R, Wang, X, Brown, I, Tiropanis, T, Hall, W. “A streaming real-time web observatory architecture for monitoring the health of social machines”, Proceedings of the 24th International Conference on World Wide Web, 2015, pp. 1149–1154, ACM.
-
17.
Kashlev, A, Lu, S, “A system architecture for running big data workflows in the cloud”, IEEE International Conference on Services Computing, 2014, pp. 51–58.
-
18.
Krishnan, K, “Data warehousing in the age of big data”, Newnes, 2013.
-
19.
Krumeich, J, Jacobi, S, Werth, D, Loos, P, “Big data analytics for predictive manufacturing control-A case study from process industry”, IEEE International Congress on Big Data, 2014, pp. 530–537.
-
20.
Logica, B, Magdalena, R, “Using big data in the academic environment”, Procedia Economics and Finance, 2015, 33, 277–286.
-
21.
Manate, B, Fortis, F, Moore, P, “Applying the Prometheus methodology for an Internet of Things architecture” IEEE/ACM 7th International Conference on Utility and Cloud Computing, 2014, pp. 435–442.
-
22.
Manzoor, A, Patsakis, C, Morris, A, McCarthy, J, Mullarkey, G, Pham, H, Bouroche, M, “CityWatch: exploiting sensor data to manage cities better”, Transactions on Emerging Telecommunications Technologies, 2014, 25(1), 64–80.
-
23.
Mishne, G, Dalton, J, Li, Z, Sharma, A, Lin, J, “Fast data in the era of big data: Twitter’s real-time related query suggestion architecture”, ACM SIGMOD International Conference on Management of Data, 2013, pp. 1147–1158, ACM.
-
24.
Mohapatra, S, K, Prasan K, S, Shih-Lin, W, “Big data analytic architecture for intruder detection in heterogeneous wireless sensor networks.” Journal of Network and Computer Applications 66, 2016, 236–249.
-
25.
Munar, A, Chiner, E, Sales, I, “A big data financial information management architecture for global banking” International Conference on Future Internet of Things and Cloud, 2014, pp. 385–388, IEEE.
-
26.
Ochian, A, Suciu, G, Fratu, O, Voicu, C, Suciu, V, “An overview of cloud middleware services for interconnection of healthcare platforms”, 10th International Conference on Communications (COMM), 2014, pp. 1–4, IEEE.
-
27.
Rosenberger, M. (2015, October). “Social customer relationship management: an architectural exploration of the components”, e-Business, e-Services and e-Society,2014, pp. 372–385. Springer, Cham.
-
28.
Pääkkönen, P, Pakkala, “Reference architecture and classification of technologies, products and services for big data systems” Big data research, 2(4), 2015, 166–186.
-
29.
Rabelo, T, Lama, M, Amorim, R, R, Vidal, J, C, “SmartLAK: A big data architecture for supporting learning analytics services”, IEEE Frontiers in Education Conference (FIE), 2015, pp. 1–5, IEEE.
-
30.
Serhani, M, A, El Menshawy, M, Benharref, A, “SME2EM: Smart mobile end-to-end monitoring architecture for life-long diseases”, Computers in biology and medicine, 68, 2016, 137–154.
-
31.
Shi, G, Wang, H, “Research on big data real-time public opinion monitoring under the double cloud architecture”, IEEE Second International Conference on Multimedia Big Data (BigMM), 2016, pp. 416–419, IEEE.
-
32.
Tang, B, Chen, Z, Hefferman, G, Wei, T, He, H, Yang, Q, “A hierarchical distributed fog computing architecture for big data analysis in smart cities”, ASE BigData & SocialInformatics, 2015, p. 28, ACM.
-
33.
Xie, Zhiwu, et al. “Towards use and reuse driven big data management.” Proceedings of the 15th ACM/IEEE-CS Joint Conference on Digital Libraries. 2015.
-
34.
Xu, D, Wu, D, Xu, X, Zhu, L, Bass, L, “Making real time data analytics availabsubmitle as a service”, 11th International ACM SIGSOFT Conference on Quality of Software Architectures (QoSA), 2015, pp. 73–82, IEEE.
-
35.
Zhou, K, Yang, S “A framework of service-oriented operation model of China′ s power system”, Renewable and Sustainable Energy Reviews, 50, 2015, 719–725.
-
36.
Zhou, Q, Simmhan, Y, & Prasanna, V, “Towards hybrid online on-demand querying of realtime data with stateful complex event processing” IEEE International Conference on Big Data, 2013, pp. 199–205
Appendix 3
Appendix 4
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Avci, C., Tekinerdogan, B. & Athanasiadis, I.N. Software architectures for big data: a systematic literature review. Big Data Anal 5, 5 (2020). https://doi.org/10.1186/s41044-020-00045-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s41044-020-00045-1